
時系列データは上下に激しく変動するものが多く、平滑化をしてプロットすることが多いです。移動平均や局所回帰1を使う方法があり、とくに移動平均は簡便で有用なので広く使われていますが、状態空間モデル(state space model)を使うこともあります。
状態空間モデルは、最初期の応用例のカルマンフィルターが1950年代のロケット制御で使われたことで広まり、研究が進んだものです2。今では工学だけではなく、金融データの分析などにも広く使われるようになりました。制御理論で使われていたものが統計解析の手法として昇華したために説明や方言が多様なのが難で、工学ではフィードバック機構のひとつとして、統計学では時系列データの逐次ベイズ推定のひとつとして説明されることが多いようです。
より広いデータ(入力)に対応できるように、より一般化した手法が提案されています。状態空間モデルのうち、線形かつ誤差項に正規分布を仮定するものがカルマンフィルターですが、粒子フィルターなどの手法でポアソン分布やコーシー分布などを扱うこともできます。本稿では統計学での説明を踏襲して概要を確認し、Rでのカルマンフィルターと粒子フィルターの実践方法を紹介します。
1 状態空間モデル
状態空間モデルはバリエーションがあり、もっとも基本的なカルマンフィルターでもパラメーターの設定に柔軟性があり、推定結果の中で参照する数字も複数になるため、ある程度の数理的な理解が必要です。詳細は必要に応じてオンラインで無料で読めるドキュメントの中妻 (2003)3などを参照するとしても、概要は把握しておきましょう。
状態空間モデルを一般化して表記すると、以下のようになります。
\[\begin{align} y_t &= h(Z_t, \alpha_t) \\ \alpha_t &= f(T_t, \alpha_{t-1}) \end{align}\]
\(y\)が観測値のベクトル、\(t\)が時点を表す添字、\(Z_t\)と\(T_t\)は観測もしくは仮定可能4な説明変数、\(\alpha\)が状態をあらわす変数のベクトルです。初期値\(\alpha_0\)の確率分布は任意に、つまり主観的に定めます。\(h\)と\(f\)は何かの確率分布に従う乱数関数です。\(t \ge 1\)のとき\(y_t\)と\(\alpha_t\)は確率変数になります。
関数\(h\)は、観測方程式 (observation equation)または測定方程式(measurement equation)または観測モデルと呼ばれています。関数\(f\)は遷移方程式(transition equation)または状態方程式(state equation)またはシステムモデルと呼ばれています。マルコフ過程になっています。どちらも典型的には誤差項をつけた線形モデルとなりますが、関数\(h\)がポアソン分布の乱数生成器になっている状態空間モデルなどもあります。
\(\alpha_{t-1}\)の確率分布と\(y_t, y_{t-1}, \cdots, y_1\)が分かっているとします。\(\alpha_t\)のフィルタリング分布\(P(\alpha_t|y_t, y_{t-1}, \cdots , y_1)\)を求めましょう。主観的事前分布と尤度関数を求めて、ベイズの定理で計算します。
\(\alpha_{t-1}\)の確率分布と遷移方程式\(f\)から、\(\alpha\)の\(1\)期先予測分布を計算します。
\[ P(\alpha_t|y_{t-1}, \cdots , y_1) = \int_{\mathbb{R}^r} P(\alpha_t|\alpha_{t-1}) P(\alpha_{t-1}|y_{t-1}, \cdots , y_1) d \alpha_{t-1} \]
これを\(\alpha_t\)の主観的事前分布に使います。分散を大きくする処理、つまり弱化をかける場合もあります。
\(\alpha\)の\(1\)期先予測分布と観測方程式\(h\)から、\(y\)の\(1\)期先予測分布を計算します。
\[ P(y|y_{t-1}, \cdots , y_1) = \int_{\mathbb{R}^r} P(y_t|\alpha_t) P(\alpha_t|y_{t-1}, \cdots , y_1) d \alpha_t \]
\(P(y_t|\alpha_t)\)は、\(y_t\)と観測方程式\(h\)から求められる尤度関数です。
これでベイズの定理でフィルタリング分布\(P(\alpha_t|y_t, y_{t-1}, \cdots , y_1)\)を計算できます。
\[\begin{align} P(\alpha_t|y_t, y_{t-1}, \cdots , y_1)P(y_t|y_{t-1}, \cdots , y_1) &= P(y_t|\alpha_t)P(\alpha_t|y_{t-1}, \cdots , y_1) \\ P(\alpha_t|y_t, y_{t-1}, \cdots , y_1) &= \frac{P(y_t|\alpha_t)P(\alpha_t|y_{t-1}, \cdots , y_1)}{P(y_t|y_{t-1}, \cdots , y_1)} \end{align}\]
これがフィルタリング分布になります。
実際の計算では\(y_t\)のフィルタリング分布を計算直後に、\(\alpha_{t}\)と\(y_{t}\)の\(1\)期先予測分布を計算することになります。\(y_t\)があればその\(1\)期先予測分布は計算できるからです。
予測分布は\(1\)に限らずもっと先まで考えることができ、\(P(\alpha_{t+s}|y_t, y_{t-1}, \cdots , y_1), \ \mbox{where} \ s \geq 1\)と書くことができます。
\[\begin{align} &P(\alpha_{t+s}|y_{t}, y_{t-1}, \cdots , y_1)\\ &= \int_{\mathbb{R}^r} \cdots \int_{\mathbb{R}^r} \bigg [ \prod^s_{j=1} P(\alpha_{t+j}|\alpha_{t+j-1}) \bigg ] P(\alpha_t|y_t, y_{t-1}, \cdots , y_1) d \alpha_t \end{align}\]
予測分布の逆となる未来の情報も取り込んだ平滑化分布\(P(\alpha_{t-s}|y_t, y_{t-1}, y_\cdots , y_1), \ \mbox{where} \ s \geq 1\)を考えることもできます。
\[\begin{align} &P(\alpha_{t-s}|y_{t}, y_{t-1}, \cdots , y_1)\\ &= \int_{\mathbb{R}^r} p(\alpha_{t-1},\alpha_{t} | y_{t}, y_{t-1}, \cdots , y_1) p(\alpha_t|y_{t}, y_{t-1}, \cdots , y_1) d \alpha_t \\ &=\int_{\mathbb{R}^r} p(\alpha_{t-1} | \alpha_{t}, y_{t}, y_{t-1}, \cdots , y_1) p(\alpha_t|y_{t}, y_{t-1}, \cdots , y_1) d \alpha_t \\ \end{align}\]
\(P(\alpha_{t-1}|y_{t}, \cdots , y_1), P(\alpha_{t-2}|y_{t}, \cdots , y_1), \cdots, P(\alpha_1|y_{t}, \cdots , y_1)\)と新しい方から順に計算していきます。リアルタイムに何かしない経済データの時系列分析では、平滑化分布を参照することが多いです。
1.1 欠損値処理
欠損値がある期は定義からフィルタリング分布をつくることはできませんが、予測分布はつくることは可能です。予測分布をフィルタリング分布として扱います5。予測分布は何期先でも作ることができるので、欠損値のある期をスキップしても観測値がある期のフィルタリング分布を作成することができます。
2 線形状態空間モデル
状態空間モデルは、線形モデルを仮定して応用されることが多いです。
観測方程式\(h\)を以下のように定義します。
\[ y_t = Z_t \alpha_t + \epsilon_t \]
\(y_t\)と\(m\)次元ベクトル、\(t\)は期を表す添字、\(Z_t\)は\(m\)行\(r\)列の行列、\(\alpha_t\)は\(r\)次元ベクトル、\(\epsilon_t\)は誤差を表す\(m\)次元の確率変数です。
観測方程式は説明変数\(Z_t\)と係数\(\alpha_t\)による線形モデルで、\(m=1\)とし、\(\alpha_t\)を一定に、\(\epsilon_t \sim \mathcal{N}\)と正規分布を仮定すると、一般線形モデル(OLS)になります。\(\alpha_t\)が可変なので計量経済学ではなく統計学における変量効果モデルの一種になり、誤差項を柔軟に仮定することができます。
遷移方程式\(f\)を以下のように定義します。
\[ \alpha_{t+1} = T_t \alpha_t + \eta_t \]
\(T_t\)は\(r\)行\(r\)列の行列、\(\eta\)は誤差を表す\(m\)次元の確率変数です。
2.1 カルマンフィルター
カルマンフィルターは、線形状態空間モデルの\(\epsilon\)と\(\eta\)と初期値に多変量正規分布を仮定したものとなります。さらに教科書にある誤差項の分散共分散行列を定めたモデルは、行列の計算で逐次推定が行える計算上の利点があります。
線形モデルの誤差項を以下のように設定します。
\[\begin{align} \eta_t &\sim \mathcal{N}_q(0, \Omega_t) \\ \epsilon_t &\sim \mathcal{N}_m(0, \Sigma_t) \end{align}\]
初期値は以下のようにします。
\[\begin{align} \alpha_1 &= \mathcal{N}_r(T_0\alpha_0, \Omega_0) \end{align}\]
誤差項を標準正規分布を使った形に書き直しましょう。
\[\begin{align} u_{t} &\overset{\scriptscriptstyle\text{i.i.d}}{\sim} \mathcal{N}_q(0, I) \\ \Sigma_t &= {}^t\!G_t G_t \\ \Omega_t &= {}^t\!H_t H_t \end{align}\]
\(u_{t}\)は\(q\)次元の標準正規分布に従う確率変数のベクトルで、\(G_t\)は\(m\)行\(q\)列、\(H_t\)は\(r\)行\(q\)列の行列になります。
観測方程式と遷移方程式は
\[\begin{align} \begin{cases} y_t &= Z_t \alpha_t + G_t u_{t} \\ \alpha_{t+1} &= T_t \alpha_t + H_t u_{t} \end{cases} \end{align}\]
となります。
誤差項については、\(G_t{}^t\!H_t = 0\)と無相関とします。また、\(G_t{}^t\!G_t\)と\(H_t{}^t\!H_t\)は、分散共分散行列になるわけで、正則行列とします。
これでモデルの設定は終わりです。
正規分布の線形結合が正規分布になることと、多変量正規分布の条件付き確率分布の公式を使うと、以下のように行列を使って求める分布を整理できます。
\[\begin{align} \alpha_t|y_{t-1}, \cdots, y_1 &\sim \mathcal{N}_r(\hat{\alpha}_t, P_t) \quad \mbox{1期先α予測分布}\\ y_t|y_{t-1}, \cdots, y_1 &\sim \mathcal{N}_m(Z_t\hat{\alpha}_t, D_t) \quad \mbox{1期先y予測分布} \\ \alpha_t|y_{t}, y_{t-1}, \cdots, y_1 &\sim \mathcal{N}_r(\hat{\mu_t}, \hat{\Sigma_t}) \quad \mbox{フィルタリング分布} \\ \hat{\alpha}_{t+1} &= \begin{cases} T_0 \alpha_0 & t = 0 \\ T_t \hat{\alpha}_t + K_t e_t & t \ge 1 \end{cases} \\ P_{t+1} &= \begin{cases} H_0 {}^t\!H_0 & t = 0 \\ T_t P_t {}^t\! L_t + H_t {}^t\!J_t & t \ge 1 \end{cases} \\ \hat{\mu}_t &= \hat{\alpha}_t + P_t {}^t\!Z_tD_t^{-1}e_t \\ e_t &= y_t - Z_t \hat{\alpha}_t \\ \hat{\Sigma}_t &= P_t - P_t {}^t\!Z_t D_t^{-1} Z_t P_t \\ L_t &= T_t - K_t Z_t \\ J_t &= H_t - K_t G_t \\ K_t &= (T_t P_t {}^t\!Z_t + H_t {}^t\!G_t)D_t^{-1} \\ D_t &= Z_t P_t {}^t\!Z_t + G_t {}^t\!G_t \end{align}\]
\(s\)期先予測分布もサンプリング手法なしに計算できます。
\[\begin{align} \alpha_{t+s} | y_t, y_{t-1}, \cdots , y_t &\sim \mathcal{N}_r(\hat{\alpha}_t(s), P_t(s)) \\ \hat{\alpha}_t(s) &= \begin{cases} \hat{\alpha}_{t + 1} & s = 1 \\ T_{t+s-1} \hat{\alpha}_t(s-1) & s \ge 2 \end{cases} \\ P_t(s) &= \begin{cases} P_{t+1} & s = 1 \\ T_{t+s-1}P_{t}(s-1){}^t\!T_{t+s-1} + H_{t+s-1} {}^t\!H_{t+s-1} & s \ge 2 \end{cases} \end{align}\]
\(y\)の\(s\)期先予測分布は以下になります。
\[\begin{align} E[y_{t+s}] &= Z_{t+s} \hat{\alpha}_t \\ V\!AR[y_{t+s}] &= Z_{t+s} P_t(s) {}^t\!Z_{t+s} + G_{t+s}{}^t\!G_{t+s} \end{align}\]
平滑化分布も同様です。
\[\begin{align} \alpha_{t-s} | y_t, y_{t-1}, \cdots , y_t &\sim \mathcal{N}_r(\tilde{\alpha}_{t-s}, Q_{t-s}) \\ \tilde{\alpha}_{t-s} &= \begin{cases} \hat{\mu}_t & s = 0 \\ \hat{\mu}_{t - s} + J^*_{t-s}(\tilde{\alpha}_{t-s+1} - \hat{\alpha}_{t-s+1}) & s \ge 1 \end{cases} \\ Q_{t-s} &= \begin{cases} \hat{\Sigma}_{t} & s = 0 \\ \hat{\Sigma}_{t-s} + J_{t-s}^* (Q_{t-s+1} - P_{t-s+1}){}^t\!J^*_{t-s} & s \ge 0 \end{cases} \\ J_{t-s}^* &= P_{t-s} {}^t\!L_{t-s}P^{-1}_{t-s+1} \end{align}\]
観測方程式の誤差項と測定方式の誤差項が直交している\(G_{t-s}{}^t\!H_{t-s}=0\)の場合は、
\[ J_{t-s}^* = \hat{\Sigma}_{t-s} {}^t\!T_{t-s}P^{-1}_{t-s+1} \]
となります。
\(y\)の平滑化分布は以下になります。
\[\begin{align} E[y_{t-s}] &= Z_{t-s} \hat{\alpha}_{t-s} \\ V\!AR[y_{t-s}] &= Z_{t-s} P_{t-s} {}^t\!Z_{t-s} + G_{t-s}{}^t\!G_{t-s} \end{align}\]
なお、平滑化の方法は色々と提案されていて、これはその一つだと理解した方が無難だと思います。
カルマンフィルターは1960年代のアポロ計画で使われた(岩田 (2017))ことで名を馳せたわけですが、当時の計算機が扱える程度の複雑さになっています。
ところでカルマンフィルターは、\((T_t, \eta_t)\)が時点に依存せず一定で、遷移方程式が定常のときは、
\[\begin{align} E[\alpha_t] &= 0 \\ V\!AR[\alpha_t] &= T\ V\!AR[\alpha_t]\ {}^tT + \Omega \Rightarrow vec(V\!AR[\alpha_t]) = [I - T \otimes T]^{-1} vec(\Omega) \end{align}\]
となります。カルマンフィルターのフィルタリング分布や平滑化分布は観測数が増えても信用区間が狭まっていかないことが多いですが、数理的に理屈がついています。
2.1.1 教科書モデルの推定例
カルマンフィルターをドル円為替レートに適用してみましょう。モデルのパラメーターは以下のようにします。
\[\begin{align} Z_t &= \begin{pmatrix} 1 & 0 \end{pmatrix} \\ G_t &= \begin{pmatrix} 0.5 & 0 & 0 \end{pmatrix} \\ T_t &= \begin{pmatrix} 1 & 1 \\ 0 & 1 \end{pmatrix} \\ H_t &= \begin{pmatrix} 0 & 0.02 & 0 \\ 0 & 0 & 0.03 \end{pmatrix} \\ \alpha_0 &= \begin{pmatrix} \mbox{直前の取引日の終値} \\ 0 \end{pmatrix} \end{align}\]
このモデルでは時点\(t\)に関わらず値は一定ですが、\(t\)によって値を変えても問題ありません。\(Z_t\)や\(T_t\)に説明変数を入れることもあります。
この教科書的な設定を入力できるパッケージが見当たらないので、ベタベタとRでコードを書いていきます。
2.1.1.1 データセット
為替のデータですが、相場が開かれていない日はNAになるので、それなりNAが入っています。
df01 <- read.table("https://wh.anlyznews.com/R/dataset/for_KF.txt", header = FALSE, skip = 2,
col.names = c("Date", "at9", "max", "min", "at17"),
colClasses = c("Date", "numeric", "numeric", "numeric", "numeric"))
date <- as.POSIXlt(df01$Date)
df02 <- subset(df01, date$mon >= 2 & date$mon < 6 & date$year == 126)
summary(df02) Date at9 max min
Min. :2026-03-01 Min. :156.5 Min. :156.5 Min. :155.5
1st Qu.:2026-03-19 1st Qu.:158.1 1st Qu.:158.3 1st Qu.:157.8
Median :2026-04-06 Median :159.0 Median :159.3 Median :158.8
Mean :2026-04-06 Mean :158.7 Mean :159.0 Mean :158.4
3rd Qu.:2026-04-24 3rd Qu.:159.5 3rd Qu.:159.7 3rd Qu.:159.2
Max. :2026-05-13 Max. :160.2 Max. :160.7 Max. :159.8
NAs :26 NAs :26 NAs :26
at17
Min. :156.3
1st Qu.:158.1
Median :159.0
Mean :158.7
3rd Qu.:159.5
Max. :160.1
NAs :26 2.1.1.2 逐次推定と平滑化の計算
実際の計算部分は以下です。分散共分散行列を記録する都合で、データフレームではなくてリストを使っています。
# 初期値を分析機関の前月の最終日の終値から決める
prior_dist_means <- with(new.env(), {
df03 <- subset(df01, date$mon == 1 & date$year == 126)
df03 <- subset(df03, complete.cases(df03))
df03 <- df03[nrow(df03), ]
c(df03$at17, 0)
})
# 行列サイズを定める変数
m <- 1
q <- 3
r <- 2
# 観測方程式
Zt <- matrix(c(1, 0), m, r)
Gt <- matrix(c(0.5, 0, 0), m, q) # 誤差項にかかる変数
# 遷移方程式
Tt <- matrix(c(1, 0, 1, 1), r, r)
Ht <- matrix(c(0, 0, 1e-2, 0, 0, 3e-2), r, q) # 誤差項にかかる変数
# 初期化
n <- nrow(df02)
y <- df02$at9 # 始値にKalman Filterをかける
alpha0 <- matrix(prior_dist_means, r, m) # 初期分布
alpha_hat <- Tt %*% alpha0 # t=1のフィルタリング分布の期待値
Pt <- Ht %*% t(Ht) # 〃の分散
r_KF <- list() # 計算結果の保存先
# 順方向のループ(内部は逐次推定になっている)
for(t in 1:n){
# 今回のモデルではtに依存させていない変数が多いが、tに依存させる場合は、配列にするなり、関数にするなりする
Dt <- Zt %*% Pt %*% t(Zt) + Gt %*% t(Gt)
Kt <- (Tt %*% Pt %*% t(Zt) + Ht %*% t(Gt)) %*% solve(Dt)
Jt <- Ht - Kt %*% Gt
Lt <- Tt - Kt %*% Zt
Sigma_hat <- Pt - Pt %*% t(Zt) %*% solve(Dt) %*% Zt %*% Pt
r_KF[[t]] <- list(
# 1期先α予測分布を保存
alpha_hat = alpha_hat, P = Pt,
# 1期先y予測分布を保存
y_hat = Zt %*% alpha_hat, D = Dt
)
if(is.na(y[t])){
mu_hat <- alpha_hat # y_tが欠損値の場合は、予測値を使う
alpha_hat <- Tt %*% alpha_hat
Pt <- Tt %*% Pt %*% t(Tt) + Ht %*% t(Ht)
} else {
et <- y[t] - Zt %*% alpha_hat
mu_hat <- alpha_hat + Pt %*% t(Zt) %*% solve(Dt) %*% et
alpha_hat <- Tt %*% alpha_hat + Kt %*% et
Pt <- Tt %*% Pt %*% t(Lt) + Ht %*% t(Jt)
}
# フィルタリング分布を保存
r_KF[[t]]$mu_hat <- mu_hat
r_KF[[t]]$Sigma_hat <- Sigma_hat
r_KF[[t]]$L <- Lt
}
# 逆方向のループ
r_KF[[n]]$alpha_tilde <- r_KF[[n]]$mu_hat
r_KF[[n]]$Q <- r_KF[[n]]$Sigma_hat
for(t in seq(n - 1, 1, -1)){
Jt_asterisk <- r_KF[[t]]$P %*% r_KF[[t]]$L %*% solve(r_KF[[t + 1]]$P)
r_KF[[t]]$alpha_tilde <- r_KF[[t]]$mu_hat + Jt_asterisk %*% (r_KF[[t + 1]]$alpha_tilde - r_KF[[t + 1]]$alpha_hat)
r_KF[[t]]$Q <- r_KF[[t]]$Sigma_hat + Jt_asterisk %*% (r_KF[[t + 1]]$Q - r_KF[[t + 1]]$P) %*% t(Jt_asterisk)
}2.1.1.3 観測値の予測分布
\(y\)予測分布を取り出して見ましょう。
プロットすると以下のようになります。
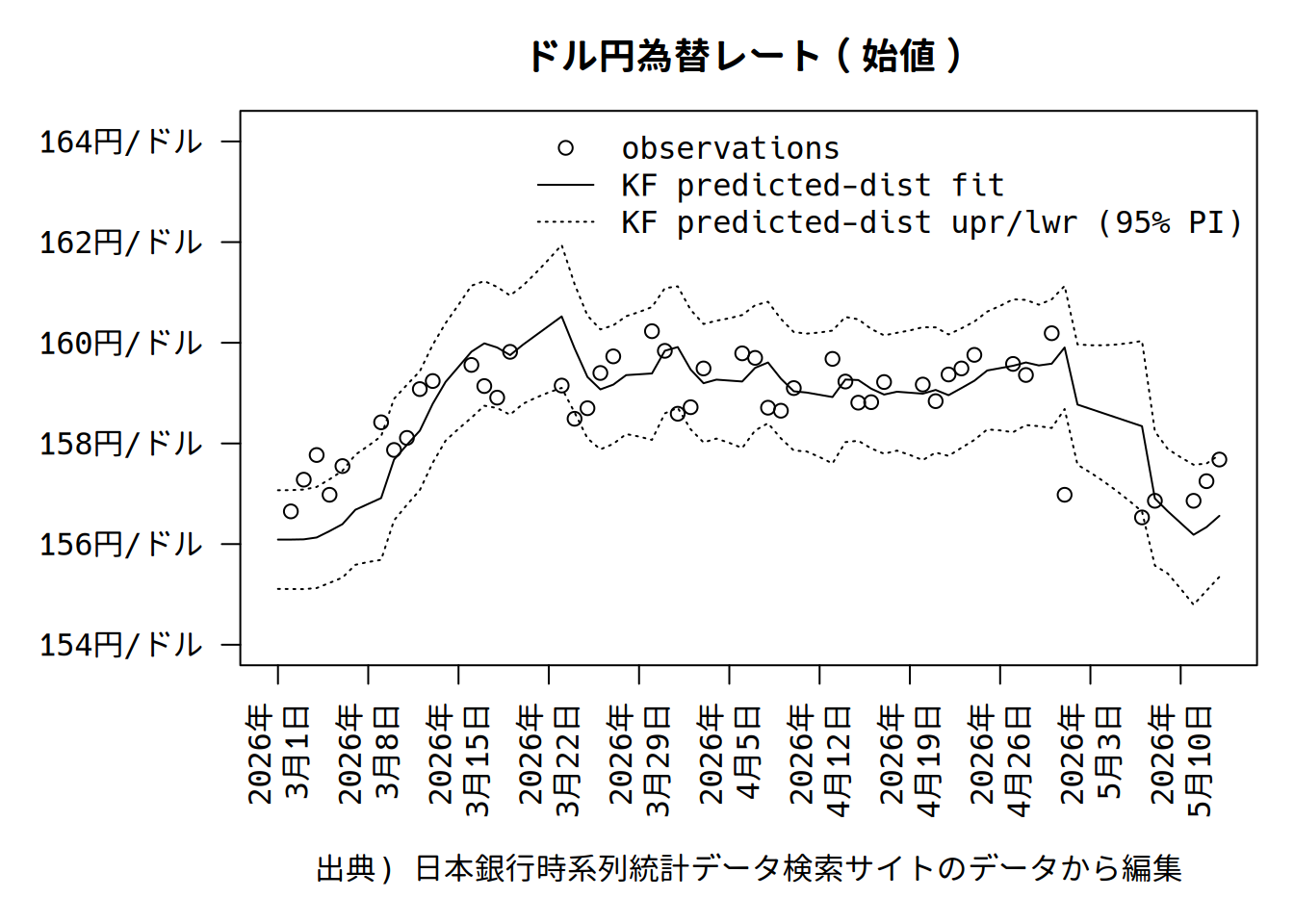
2.1.1.4 観測値の平滑化分布
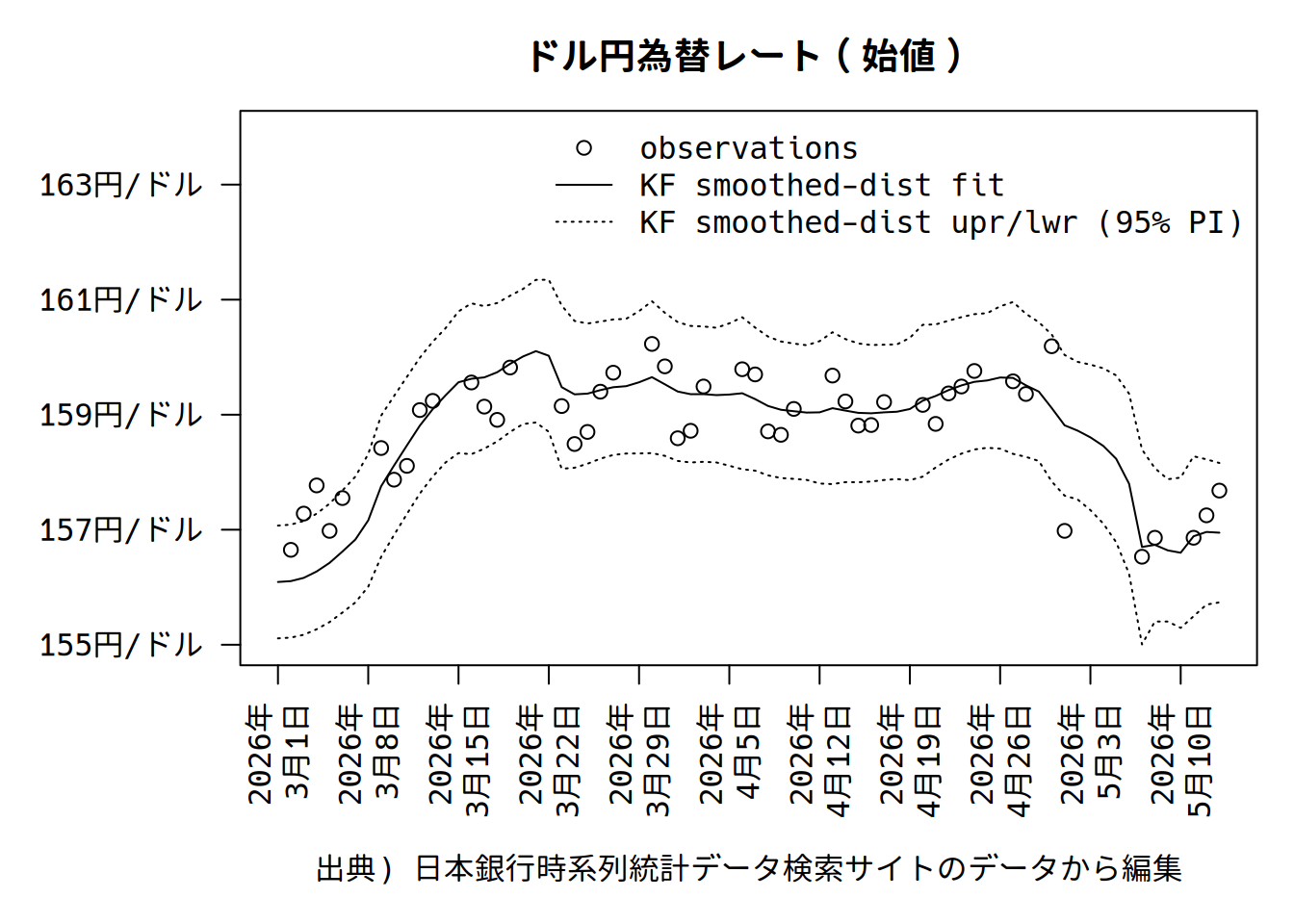
\(y\)平滑化分布を\(\tilde{\alpha}_t\)平滑化分布から計算しましょう。
smoothed_fit <- numeric(n)
smoothed_sd <- numeric(n)
for(t in n:1){
alpha_tilde <- r_KF[[t]]$alpha_tilde
Q <- r_KF[[t]]$Q
P <- r_KF[[t]]$P
smoothed_fit[t] <- Zt %*% alpha_tilde
smoothed_sd[t] <- sqrt(Zt %*% P %*% t(Zt) + Gt %*% t(Gt))
}プロットを行うと、ちょっとですが、滑らかになったのがわかります。
2.1.2 最尤法によるパラメーターの推定
ここまで紹介したモデルでは、誤差項の分散共分散行列\(\Sigma_t=G_t{}^t\!G_t\)と\(\Omega_t=H_t{}^t\!H_t\)は分析者が設定するパラメーターでした。 線形代数で計算するためには必要な制約ですが、統計解析で用いるときは以下の対数尤度関数を最尤法にかけて推定する方が扱いやすいでしょう。
観測数を\(n\)として、尤度は観測方程式の誤差を考えて
\[ P(y_n, y_{n-1}, \cdots, y_1 |\theta) \propto \prod^n_t |D_t|^{-\frac{1}{2}} e^{-\frac{1}{2}{}^t\!(y_t - Z_t \hat{\alpha}_t)D_t^{-1}(y_t - Z_t \hat{\alpha}_t)} \]
となるので、逐次推定ではなくなりリアルタイム性は失いますが、最尤法でパラメーターを推定できます。
2.1.2.1 パッケージを使った推定例
KFASは正規分布を含めた指数分布族をサポートする状態空間モデルの推定ができるパッケージで6、最尤法で推定するようにつくってあります。典型的なモデルであれば、簡単に組み合わせて設定、推定することができますが、まずは明確に行列をパラメーターに与えて使ってみましょう。
library(KFAS)
# 観測方程式の多変量正規分布に従う誤差項の分散共分散行列; NAで推定するパラメーターであることを指定
Ht <- matrix(NA, 1, 1)
# {状態の数}行×{ノイズの数}列の遷移方程式の誤差項にかかる行列
Rt <- matrix(c(1, 0, 0, 1), 2, 2)
# 遷移方程式の多変量正規分布に従う誤差項の分散共分散行列
# {ノイズの数}行×{ノイズの数}列; NAで推定するパラメーターであることを指定
Qt <- matrix(c(NA, 0, 0, NA), 2, 2)
# 状態変数の初期値の期待値
a1 <- matrix(prior_dist_means, 2, 1)
# 状態変数の初期値の分散
P1 <- matrix(c(1, 0, 0, 1), 2, 2)
# 観測値の末尾に欠損値を追加(len期先まで予測分布が計算される)
y <- df02$at9
date <- df02$Date
len <- 10
if(0 < len){
y <- c(y, rep(NA, len))
date <- c(date, seq(date[length(date)] + 1, date[length(date)] + len, "days"))
}
# 推定するモデルの構築
model_KFAS <- SSModel(y ~ -1 + SSMcustom(
Z = Zt, T = Tt, R = Rt, Q = Qt, a1 = a1, P1 = P1), H = Ht) # この例では大差ないが、P1 = P1の代わりにP1inf = diag(2)を指定すると、初期値の分散を無限大として計算する
# 最尤法で推定(optimに渡すパラメーターが与えられている; 行列に挿入したNAと数をあわせる)
fit_KFAS <- fitSSM(model_KFAS, inits = c(1, 1, 1), method = "L-BFGS-B")
# 状態変数と観測値の推定値の系列を得る
# stateは状態変数、signalは観測値を表し、それぞれのフィルタリング分布と平滑化分布を計算するように指定
r_KFAS <- KFS(fit_KFAS$model, filtering = c("state", "signal"), smoothing = c("state", "signal"))
# 平滑化された予測値を得る
r_predict <- predict(fit_KFAS$model, interval = "predict", level = 0.95)観測値のベクトルの末尾にNAを10追加することで7、未来を10期先まで予測をさせています。
分散共分散行列が最適化されたため、プロットの形状も微妙に変わりました。
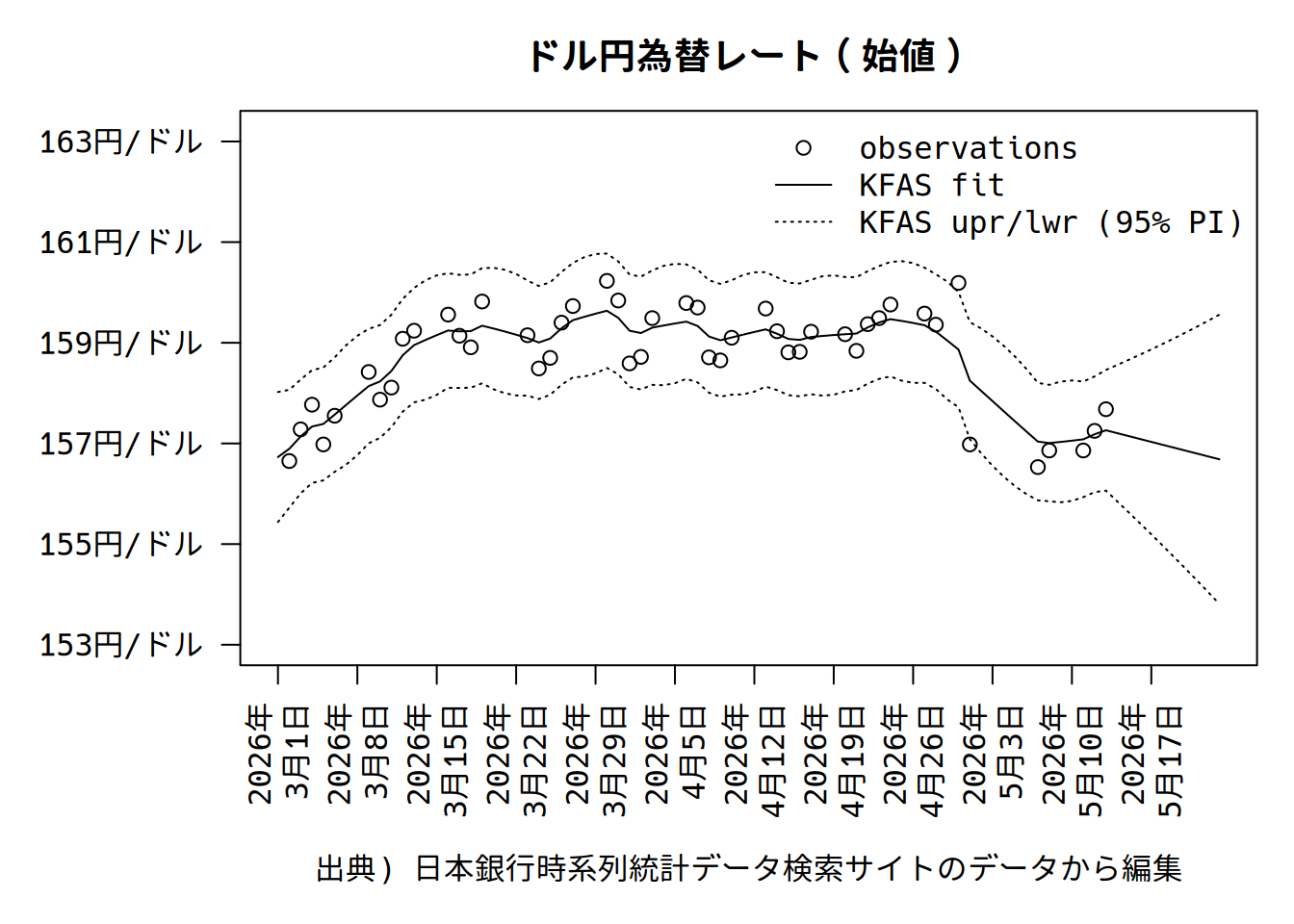
KFSの結果オブジェクトの中のmodel$Qとmodel$Hで、推定された分散共分散行列を確認できます。
, , 1
[,1] [,2]
[1,] 0.08248627 0.0000000000
[2,] 0.00000000 0.0004320935, , 1
[,1]
[1,] 0.2519204またKFSの結果オブジェクトの中には、引数によって以下の数値が入っています。
| 推定量 | 期待値 | 分散共分散行列 |
|---|---|---|
| 状態変数の1期先予測 | a |
P |
| 観測値の1期先予測 | m |
P_mu |
| 状態変数のフィルタリング分布 | att |
Ptt |
| 状態変数の平滑化分布 | alphahat |
V |
| 観測値の平滑化分布 | muhat |
V_mu |
今回の分析結果から\(y\)の1期先予測分布を得る場合、r_KFAS$muで期待値を、sqrt(r_KFAS$P_mu[1,,])で標準誤差を参照します。
2.1.3
KFASパッケージSSMcustom利用tips
より複雑な分析ができないか検討するときのために、今回は使わなかったところを含めて、SSMcustomのパラメーターの指定方法で特徴的なところをあげておきます。
- 数理モデルで行列になっているパラメーターは、時点\(t\)によらず一定の場合は行列で指定します。時点ごとに変わる外生変数を\(T_t\)に入れ、\(t-1\)期の状態変数をその係数として\(t\)期の状態を説明させたいときなど、\(t\)ごとに行列の成分が変わる場合は、配列(
array)で設定します。配列の添字は行、列、時点の順になります。 - 誤差項の多変量正規分布の次元(
KFASのエラーメッセージの変数k)は直接指定できず、分散共分散行列のサイズから判別されます。 - 最尤法で推定させるパラメーターの指定は、簡単には行列の成分に
NAを入れます。fitSSMの引数initsで指定する初期値の数と、NAの数はあわせてください。NAはSSMcustomの引数HとQとZで入れる配列にのみ入れられます。やや煩雑な方法で、Tの成分を最尤推定するパラメーターとして扱うこともできます8。
2.1.4
KFASを簡単に利用する方法
KFASパッケージをなるべくカルマンフィルターの説明とスクラッチのコードとの対応が分かるように使いましたが、平滑化するだけならば以下で簡単に済ます事ができます。
library(KFAS)
model_KFAS <- SSModel(y ~ SSMtrend(1, Q=NA), H=NA)
fit_KFAS <- fitSSM(model_KFAS, inits = c(0, 0), method = "L-BFGS-B")
r_predict <- predict(fit_KFAS$model, interval = "predict", level = 0.95)季節調整も簡単に追加できます。
library(KFAS)
model_KFAS <- SSModel(y ~ SSMtrend(1, Q = NA) +
SSMseasonal(period = 7, Q = NA, sea.type = "dummy", P1 = diag(6) * 100),
H = NA)
fit_KFAS <- fitSSM(model_KFAS, inits = rep(0, 8), method = "L-BFGS-B")
r_predict <- predict(fit_KFAS$model, interval = "predict", level = 0.95)これで観測方程式に季節調整の項が追加されました。引数periodで周期を、sea.typeで季節調整の方法を指定します。
最尤法で推定するパラメーターが6つ増えたことに注意してください。sea.type = "dummy"の場合、ダミー変数を用いるので、季節の数から1を減じたパラメーターを推定することになります。trigonometricを入れると三角関数を用いることで推定パラメーターの数を抑制できますが、周期性があっても綺麗な波動をしているとは限らないので、dummyを入れておきましょう。
今回の例ではP1を指定しないと警告が出ましたが、データによっては省略しても問題ないです。
2.2 その他の線形状態空間モデル
線形状態空間モデルの応用(もしくは線形状態空間モデルに書き直せる分析)は色々とあります。可変係数回帰モデル(time-varying coefficients regression model)、動学的因子モデル、自己回帰移動モデル(ARMA)、マルコフ混合分布モデル(HMM)です910。
KFASパッケージでもSSMregression関数とSSMarima関数を用意することでサポートしており、SSModelに引数として渡すことで利用することができます。詳しくはKFASパッケージのvignettesを参照してください。
3 非線形状態空間モデル
観測方程式もしくは状態方程式が非線形の場合を考えることもできます。最尤法やEMアルゴリズムやマルコフ連鎖モンテカルロ法(MCMC)などの多様な推定方法があります。
3.1 観測方程式が指数分布族の確率分布
観測方程式が指数分布族の確率分布に従う場合(i.e. glmで推定できるモデル)はKFASパッケージが使えるので推定が容易です。
KFASのvignettesにある例のそのままですが、イギリスのシートベルト着用義務(law)とバンの運転手の死亡者数(VanKilled)の分析です。
library(KFAS)
model_van <- SSModel(VanKilled ~ law + SSMtrend(1, Q = list(matrix(NA))) +
SSMseasonal(period = 12, sea.type = "dummy", Q = NA),
data = Seatbelts, distribution = "poisson")
# Estimate variance parameters
fit_van <- fitSSM(model_van, c(-4, -7), method = "BFGS")
model_van <- fit_van$model
# use approximating model, gives posterior modes
out_nosim <- KFS(model_van, nsim = 0)
out_nosim
# State smoothing via importance sampling
out_sim <- KFS(model_van, nsim = 1000)
out_simこの例ではdistribution = "poisson"で、観測方程式にポアソン回帰が指定されています。他にbinomial(二項分布/ロジットモデル),
negative binomial(負の二項分布),
gamma(ガンマ分布),
gaussian(正規分布)が指定できます。
ポアソン回帰は、期待値と分散がネイピア数の線形予測子(linear predictor)乗になるオーソドックスなモデルになります。線形予測子は、シートベルト義務の有無、状態変数のトレンド、別の状態変数の季節調整値で構成されています。季節調整はダミー変数を使ったもので、周期関数は使っていません。
死亡者数は長期減少傾向と季節変動があって、プロットしてもシートベルト着用義務の効果があるのか無いのかよくわかりませんが、トレンドと月ごとの変動を統制すると微妙に効果が見えてきます。
4 粒子フィルター
パーティクルフィルターもしくは逐次モンテカルロ法は、尤度関数があれば推定できるシミュレーション手法です。アルゴリズムは単純ですが、誤差項にコーシー分布を仮定した線形モデルでも、非線形モデルでも逐次推定できます。カルマンフィルターと比較して計算量が多くなることが欠陥ですが、最近の計算機で問題になることは殆ど無いでしょう。詳しい説明は矢野 (2014)などを参照してください。
粒子フィルターの先駆的研究Kitagawa (1998)の最初の例のモデルをカルマンフィルターで使ったデータセットに当てはめてみましょう。
\[\begin{align} \nu_t &\sim \mathcal{Cauchy}(0, \tau_t)\\ \eta_t &\sim \mathcal{N}(0, \theta_t)\\ \epsilon_{\tau t}, \epsilon_{\theta t} &\sim \mathcal{U}(0.9, 1.1)\\ Y_t &= X_t + \eta_t \quad \mbox{(観測方程式)} \\ X_{t+1} &= X_t + \nu_t \quad \mbox{(遷移方程式)} \\ \theta_{t+1} &= g_\theta(\theta_t, \epsilon_{\theta t})\\ \tau_{t+1} &= g_\tau(\tau_t, \epsilon_{\tau t})\\ \end{align}\]
裾野の厚いコーシー分布は、金融データなどで当てはまりが良いことが知られています。
# シミュレーション技法なので、seed値は設定しておく
set.seed(406149)
# 仮定するsystem noiseのνはコーシー分布
nu <- function(location, log_tau2) rcauchy(length(log_tau2), location = location, scale = sqrt(10^log_tau2))
# 観測誤差は正規分布
calcWeights <- function(y, x, sd){
p <- dnorm(y, mean = x, sd = sd)
p / sum(p)
}
y <- df02$at9
date <- df02$Date
n <- length(y)
# M: 各期でサンプリングする数
# osa: 各期の1期先予測分布
# x: 各期でサンプリングした値
# log_tau2: 各期でサンプリングに使う分布のパラメーター/x[i,j]ごとにある/log(tau^2, 10)
# w: 各期でリサンプリングに使うウェイト/尤度
# theta: 観測誤差の標準偏差
M <- 201
# 初期値を設定
w <- theta <- log_tau2 <- x <- osa <- matrix(NA, M, n)
log_tau2[, 1] <- runif(M, min = -8, max = -2)
# log_tau2[, 1] <- -4.5
theta[, 1] <- runif(M, min = 1e-6, max = 2)
# theta[, 1] <- 1
osa[, 1] <- x[, 1] <- rnorm(M, mean = prior_dist_means[1], sd = 4)
# 始点のウェイトは雑につくる
w[, 1] <- calcWeights(ifelse(is.na(y[1]), prior_dist_means[1], y[1]), x[, 1], sd = theta[, 1])
# パラメーターの誤差を大きくして、縮退しないようにする関数
g <- function(x) x*runif(M, min = 0.9, max = 1.1)
# フィルタリング分布を計算
for(j in seq(2, n)){
# 1期先予測分布をつくる
osa[, j] <- x[, j] <- nu(x[, j - 1], log_tau2[, j - 1])
# フィルタリング分布にする
if(is.na(y[j])){
# 欠損値のときは予測分布をそのまま使う
log_tau2[, j] <- log_tau2[, j - 1]
theta[, j] <- theta[, j - 1]
w[, j] <- w[, j - 1]
} else {
# リサンプリング用のウェイトをつくる
w[, j] <- calcWeights(y[j], x[, j], sd = theta[, j - 1])
# リサンプリング
i <- sample.int(M, replace = TRUE, prob = w[, j])
x[, j] <- x[i, j]
# 縮退防止で粒子のばらつきを増す
log_tau2[, j] <- g(log_tau2[i, j - 1])
theta[, j] <- g(theta[i, j - 1])
}
}状態変数のフィルタリング分布の計算ができました。
各期の平均と中央値と95%信用区間の計算は以下のように計算できます。コーシー分布を使っている都合、平均より中央値を見た方が良さそうです。
x_mean <- apply(x, 2, mean)
x_median <- apply(x, 2, median)
x_quantiles <- apply(x, 2, function(x) quantile(x, probs = c(0.025, 0.975)))平滑化分布を計算します。構造的にはフィルタリング分布と同じなのですが、過去の粒子も推定に用いることで滑らかにします。
L <- 5
s <- matrix(NA, M*(2*L+1), n)
for(j in 1:n){
columns <- max(1, j - L + 1):min(n, j + L - 1)
i <- sample.int(M, replace = TRUE, prob = w[, j])
tmp <- sapply(columns, function(k){
x[i, k]
})
s[1:length(tmp), j] <- tmp
}
s_median <- apply(s, 2, median, na.rm = TRUE)
s_quantiles <- apply(s, 2, function(x) quantile(x, probs = c(0.025, 0.975), na.rm = TRUE))観測値の1期先予測分布も計算してみましょう。
yp <- matrix(NA, M, n)
for(j in 1:n){
# i <- sample.int(M, replace = TRUE)
yp[, j] <- osa[, j] + theta[, j] * rnorm(M)
}
yp_median <- apply(yp, 2, median)
yp_quantiles <- apply(yp, 2, function(x) quantile(x, probs = c(0.025, 0.975)))プロットすると相場が大きく動くときに信用区間が広くなっていることがわかります。誤差項の分散を逐次推定しているためです。
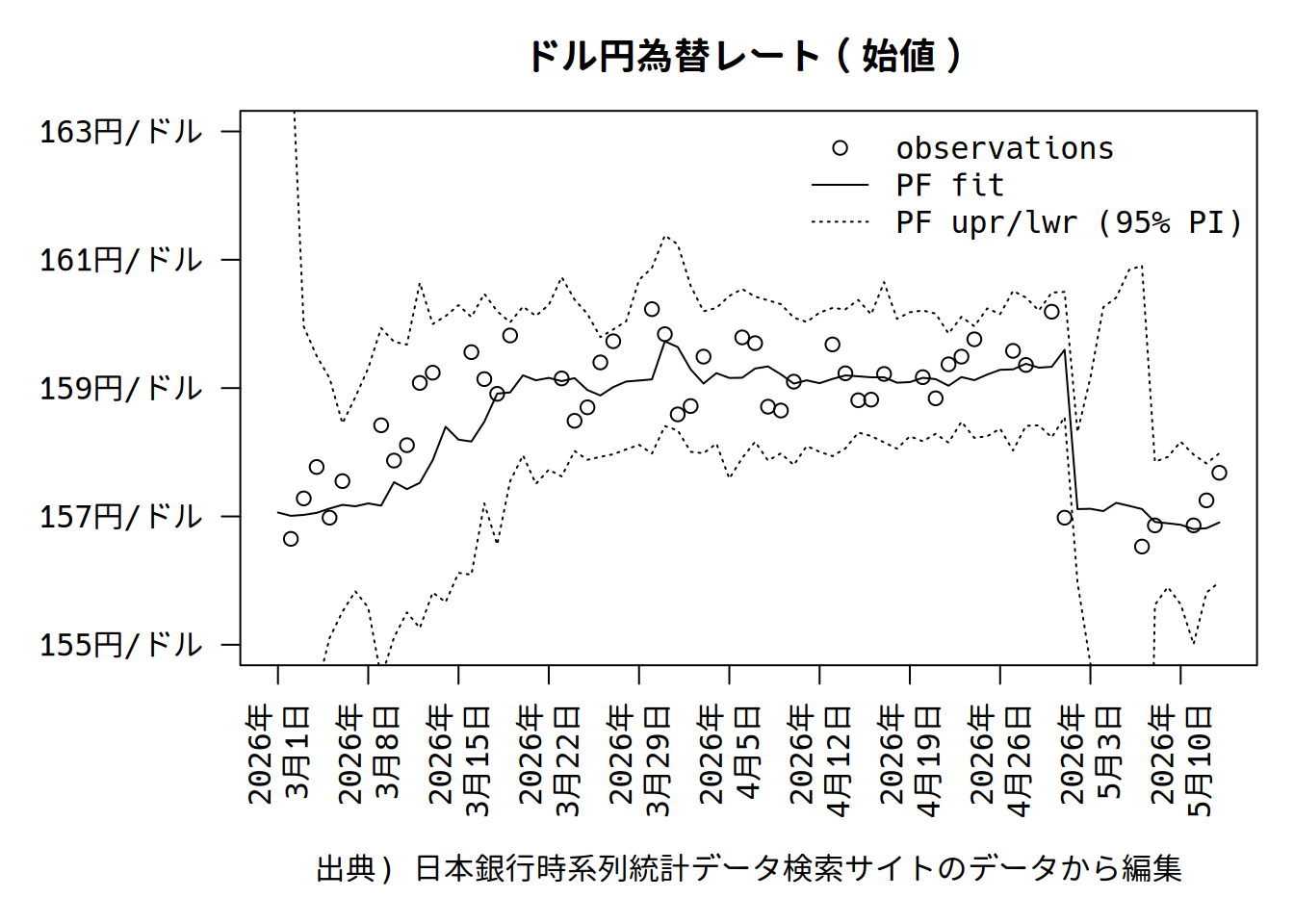
予測分布に平滑化をかけることもできます。
L <- 5
yp_s <- matrix(NA, M*(2*L+1), n)
for(j in 1:n){
columns <- max(1, j - L + 1):min(n, j + L - 1)
i <- sample.int(M, replace = TRUE, prob = w[, j])
tmp <- sapply(columns, function(k){
osa[i, k] + theta[i, k] * rnorm(M)
})
yp_s[1:length(tmp), j] <- tmp
}
yp_s_median <- apply(yp_s, 2, median, na.rm = TRUE)
yp_s_quantiles <- apply(yp_s, 2, function(x) quantile(x, probs = c(0.025, 0.975), na.rm = TRUE))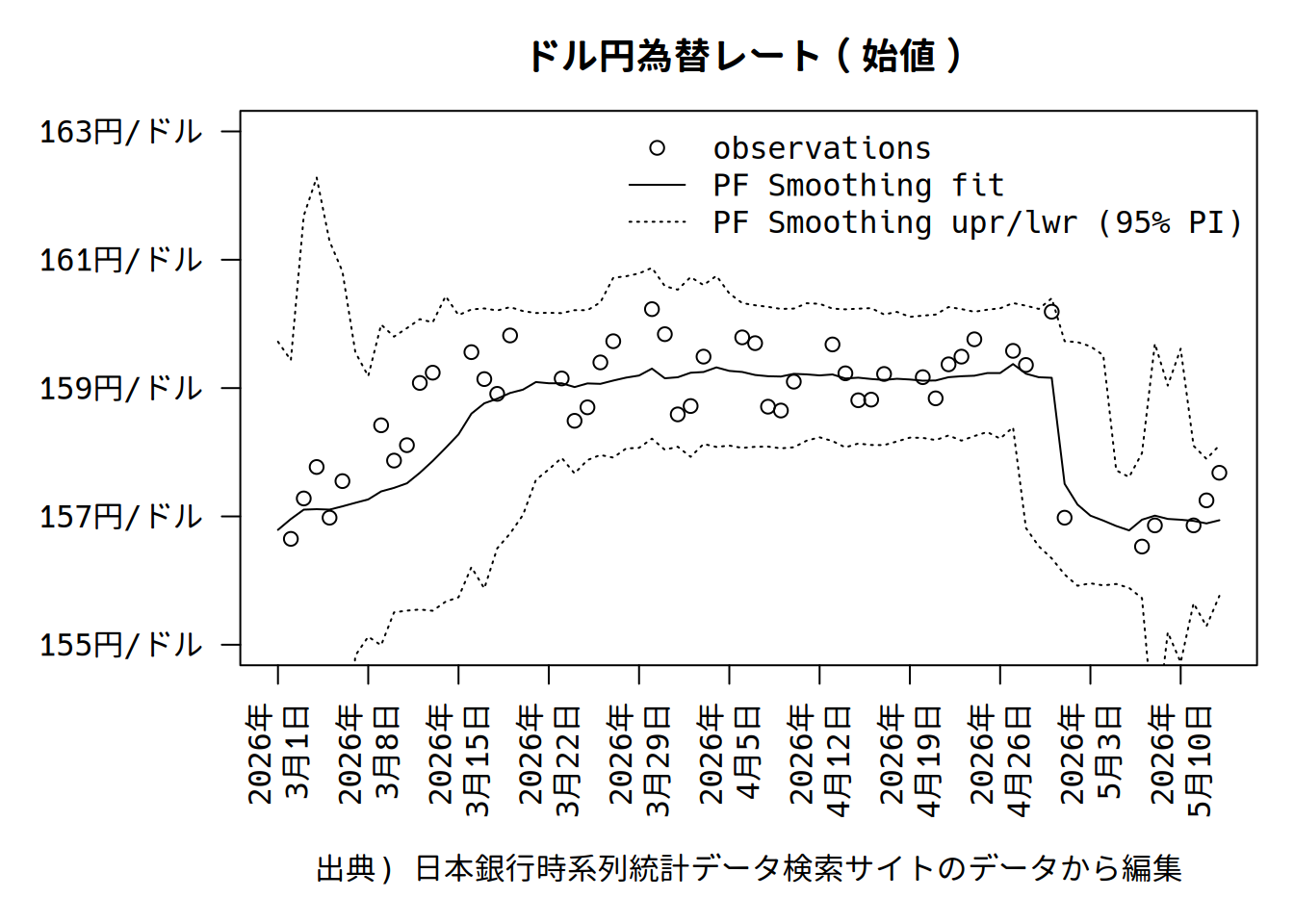
それらしいプロットになりました。
名前を冠しているKálmánの貢献が大きいですが、発想はそれ以前よりあったそうです。↩︎
本稿の説明は、中妻 (2003)の9.2節と9.3節の状態空間モデルの説明に大部分を依拠しています。本稿で省略した証明などはそこに書かれています。↩︎
\(t\)によらず常に一定の\(1\)と\(0\)による行列を仮定するのが典型です。↩︎
北川 (2019) 「時系列解析における状態空間モデルの利用」統計数理, Vol.67(2), pp.181–192↩︎
Rの状態空間モデルのパッケージは色々とあった(Tusell (2011))のですが、以前の人気パッケージでメンテナンス終了しているものもあり、現在は機能や人気で
KFASが無難な選択です。↩︎観測値の欠損しか補定されないので、パラメーターを配列で渡す場合は、予測する時点まで配列を拡張する必要があります。↩︎
宣言部が
function(pars, model, ...)であり、引数のリストmodelの中の配列Tをparsに基づいて(例えばT[1,1,]<-pars[1]と言うように)更新し、modelを戻り値とするカスタマイズ関数を、fitSSM関数のupdatefn引数で渡します。カスタマイズ関数では、model$Qやmodel$Hに入ったNAの値もparsに基づいて負にならないように更新する必要があり、model$T、model$Q、model$Hなどがarray型でなければならないことに注意してください。また、試した限りですが、上手く収束させるのは難しいようです。↩︎中妻 (2003) pp.279–283に、線形状態空間モデルの変数をどのようにすれば、これらのモデルと見做せるかの説明があります。↩︎
北川 (2019) に、中妻 (2003)に無い応用方法の紹介があります。↩︎