
Cleveland, Cleveland, McRae and Terpenning (1990)1のアルゴリズムSTLによる時系列データの季節調整は広く行われており、Rでもビルトイン関数で手軽に行うことができます。利用にあたり周期の長さ以外のパラメーターを指定する必要もほとんど無いでしょう。しかしながら、何をやっているのか説明を求められるときも人生で一回ぐらいはあるかも知れません。稀有な機会に備えて、STLの概要の理解を試みます。
1 データセット
推定のためのデータセットを先に準備します。
df01 <- with(new.env(), {
# 気象庁が公開している調布市の気候データのコピー
df01 <- read.table("http://wh.anlyznews.com/R/dataset/data_weather.csv", sep = ",", skip = 5, colClasses = c("Date", rep("numeric", 14)))[, c(1, 2, 5, 9, 13)]
# 英語でラベルをつける
colnames(df01) <- c("Date", "temp.avg", "precipitation", "sunshine", "pressure.avgs")
# 週ごとのデータに変換
plt <- as.POSIXlt(df01$Date)
l <- sprintf("Y%4d W%02d", plt$year + 1900, plt$yday %/% 7 + 1)
r <- tapply(df01[, -1], l, \(r){
apply(r, 2, mean, na.rm = TRUE)
})
m <- matrix(unlist(r), ncol = 4, byrow = TRUE,
dimnames = list(unique(l), colnames(df01)[-1]))
# 行番号の列を付与しておく
m <- cbind(1:nrow(m), m)
colnames(m)[1] <- "t"
as.data.frame(m)
})
cycle_length <- 53日次データなのですが、うるう年の処理が煩雑になるので週次に変換しました。
2 平滑化アルゴリズム
STLは2種類の平滑化アルゴリズムを組み合わせて処理しており、先に平滑化アルゴリズムを把握する方が理解しやすいです。
2.1 移動平均
もっとも基本的な平滑化アルゴリズムは、移動平均です。確率的な誤差を小さくできるのと、移動平均の期間とデータの周期性が一致すれば、周期変動を打ち消せて有用な上に、簡単に実装できるので広く使われています。
長さ\(N\)の系列\({y_1, y_2, \cdots, y_N}\)に対する期間\(n\)の後方移動平均(simple moving average)は、
\[ SMA_n(y_t) = \frac{1}{n} \sum^{t + n - 1}_{s=t} y_{s} \quad \mbox{where} \ \ 1 \leq t \leq N - n + 1 \]
と書くことができます。このままでは右の端点および計算に使う値に欠損値が含まれる場合は定義されないのと、トレンド変化にラグが出るのが欠点です。
\(n\)が3以上の奇数であれば中心化\(n\)期移動平均(centered \(n\)-period moving average)をとることができます。\(n = 2m + 1\)となるように\(m\)を置いて、
\[ CMA_n(y_t) = \frac{1}{n} \sum^{t + m}_{s=t-m} y_{s} \quad \mbox{where} \ \ m \lt t \lt N - m, \ m = \frac{n - 1}{2} \]
と書くことができます。左右の端点および計算に使う値に欠損値が含まれる場合は定義されないので、実用上は工夫が要ります。
Rではfilter関数を用いると簡単に計算することができます2。
cma <- filter(df01$temp.avg, rep(1/cycle_length, cycle_length), method = "convolution", side = 2, circular = FALSE)第1引数は移動平均をとる系列で、df01[, 2:4]のようにデータフレームなどで複数の系列を同時に指定できます。第2引数はウェイトで、移動平均の期間の逆数を割り当てています。method = "convolution"はデフォルトで、ウェイト付きの和をとります。side = 2は中心化の指定で、side = 1で後方移動平均になります。circular = TRUEにするとNAの値は戻さず削除されます。
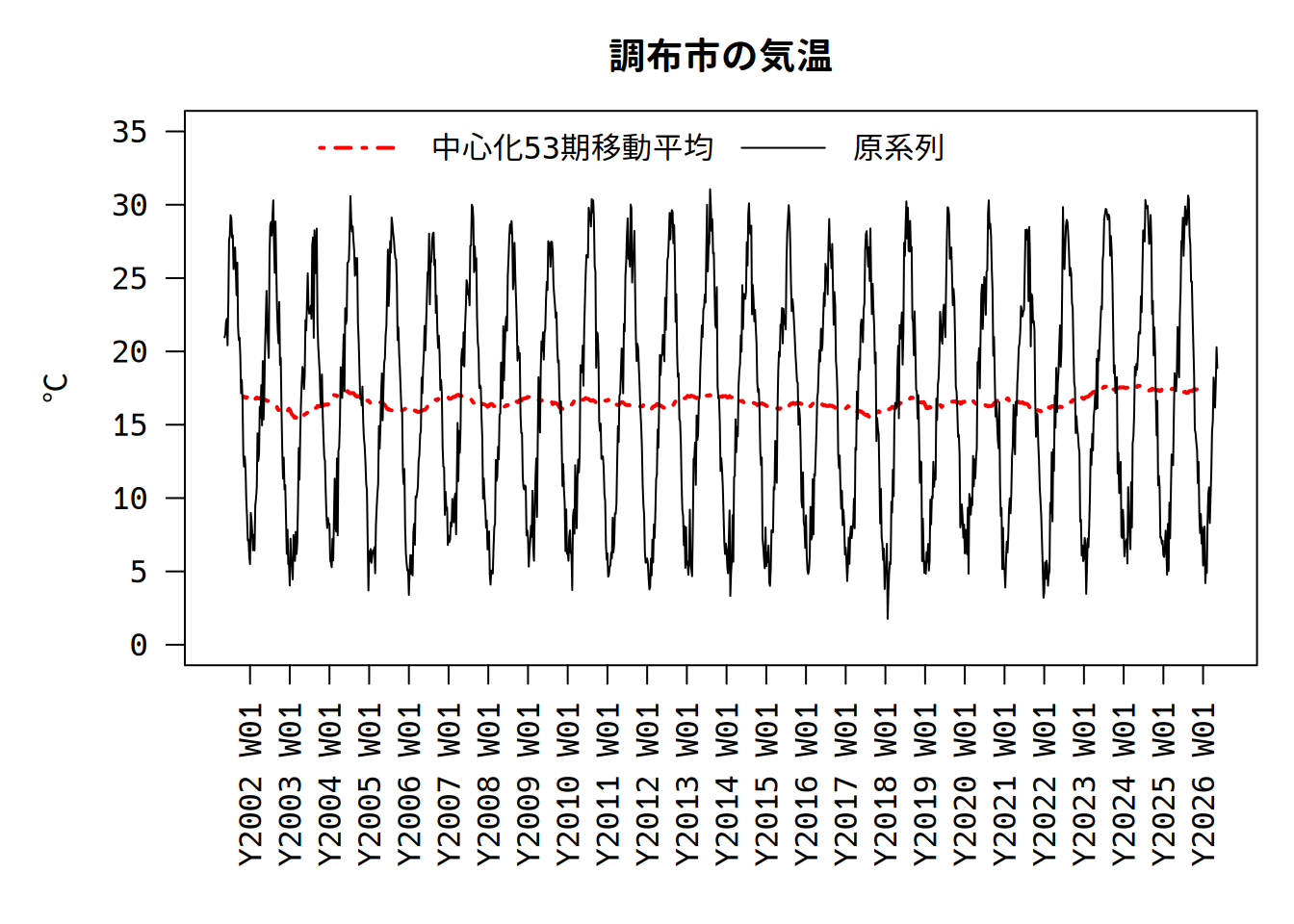
周期をあわせたので上手く季節調整されていますが、両端付近が欠損値となっています。
2.2 局所回帰(Lo(w)ess)
移動平均よりも手の込んだ方法として、局所回帰(Lo(w)ess)があります。中心化移動平均をウェイト付き最小二乗法(WLS)で推定する手法です。ウェイトを設定する場合はLowess3、しない場合はLoessと使い分けるべきな気がしますが、どちらもLoessと書かれることが多いようです。
幾つか欠損値があっても計算することができ、左右の端点の値も出ます。
\[\begin{align} \newcommand{\argmin}{\mathop{\rm arg~min}\limits} \hat{\beta(t)} = &\argmin_{\beta} \sum\nolimits_{s \in T} \delta_s w_s(x_t) \big(y_t - \sum^d_{i=0} \beta_i (x_t - x_s)^i \big) \\ \end{align}\]
\(T\)は観測値を表す添字の集合、\(x\)は時点をあらわす変数です。同じ時点の観測値が2つ以上ない場合は、\(x_t = t\)と考えて問題ないです。\(d\)は0以上3以下の任意の次数で、1もしくは2が使われる事が多いようです。\(q\)は、局所回帰に用いるサブサンプルを指定する変数です。
\(\delta_s\)は推定に頑強性を与えるための係数です。推定にFGLSを用いると、最初の推定では1が入り、2回目以降の推定ではその前の推定の予測値と観測値の差になる残差\(R_t\)の大きさから計算されます。例えば残差の絶対値の中央値の6倍を\(h\)として、
\[ \delta_t = \bigg(1 - \min\bigg(\frac{|R_t|}{h}, 1\bigg)^2\bigg)^2 \]
と計算されます。
\(w_s(x_t)\)は、\(x_t\)と\(x_s\)の距離に応じたウェイトです。推定に用いる\(\{x_s\}_{s \in T}\)の要素\(x_s\)と\(x_t\)の距離を\(dist(t)_s\)と置きます。\(\{dist(t)_s\}_{s \in T}\)の中で、もっとも遠い値を\(\lambda_n(x_t)\)、\(q\)番目に遠い値を\(\lambda_q(x_t)\)と置きます。サンプルサイズを\(n\)と置いて、
\[\begin{align} \lambda(x_t) &= \begin{cases} \lambda_q(x_t) & (q \leq n) \\ \lambda_n(x_t)\frac{q}{n} & (q > n) \end{cases}\\ w_s(x_t) &= \bigg( 1 - \min\bigg( 1, \frac{|x_t - x_s|}{\lambda(x_t)} \bigg)^3 \bigg)^3 \end{align}\]
と定義します。\(q\)が小さいと時点が遠い観測値のウェイトが小さくなり、また、ゼロウェイトの観測値が増えて、実質的に推定に用いる観測値が少なくなります。
\(\hat{\beta(t)}\)はベクトルで、\(\hat{\beta(t)}_0\)が推定された平均値、求める値になります。
Rではloess関数が用意されています。
span <- 0.5
degree <- 1
r_loess <- loess(temp.avg ~ t, df01, span = span, degree = degree, normalize = FALSE)spanは局所回帰に用いる区間を指定する変数で、比率指定なので0より大きく1以下の値を与えます。サンプルサイズは1326なので、span
= 0.5を指定すると、上の説明の\(q\)が663となります。degreeは次数で、説明では\(d\)に相当します。normalizeは説明にあわせるためにFALSEにしています。今回は使っていませんが、lm関数と同様にweightsを入れられるので、説明の\(\delta_t\)を計算すればlowessにすることができます。
上の説明で\(\hat{\beta(t)}\)の集合となるr_loess$fittedをプロットし、平滑化した値を確認します。
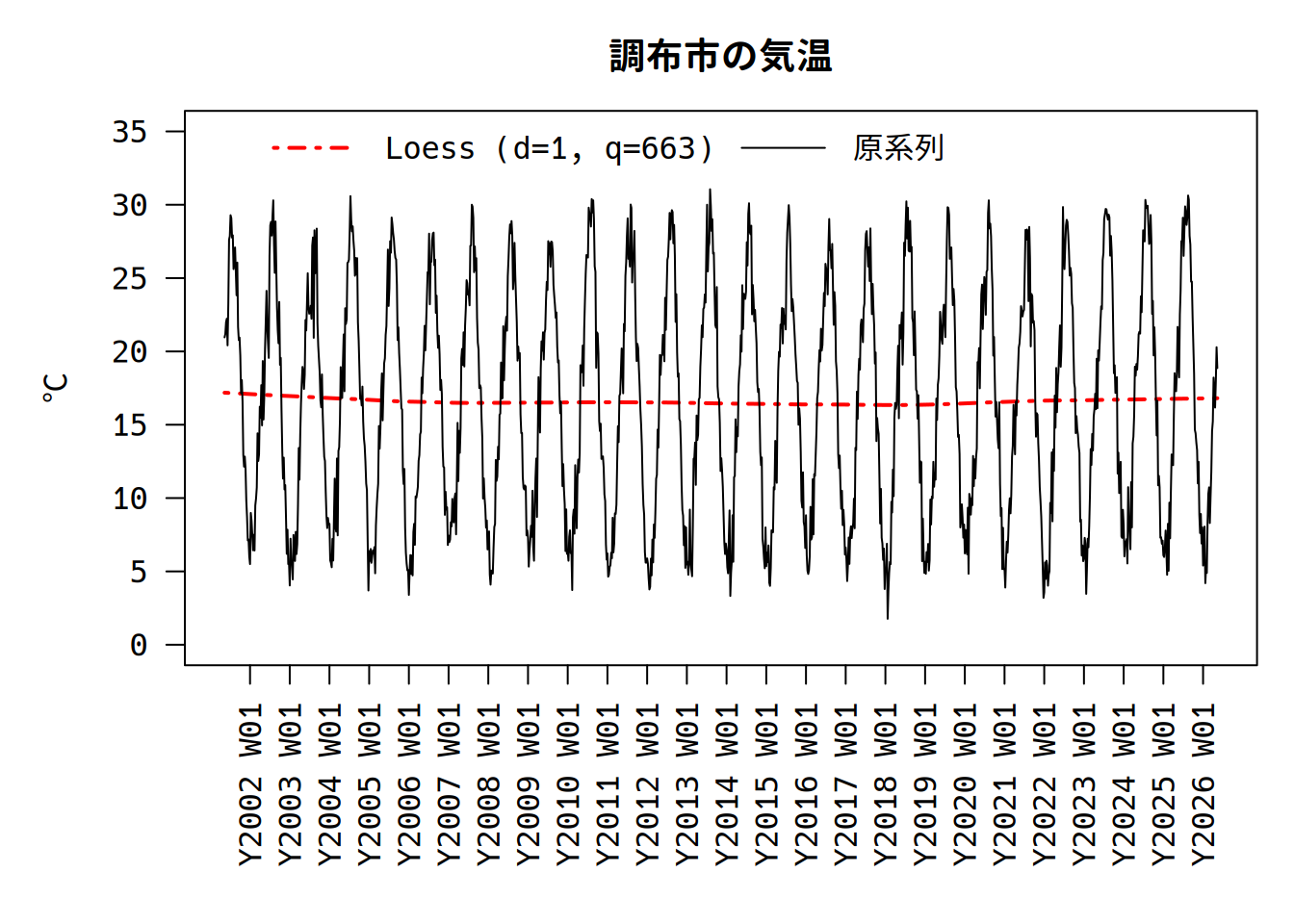
両端付近に欠損値はなくなりました。なお、spanが短いと季節変動が取り切れず、とくに両端付近で目立つようになります。
3 季節調整(STL)
本題の季節調整(STL)に入ります。原系列\(\{y_t\}\)をトレンド\(\{\tau_t\}\)、季節変動\(\{s_t\}\)、残余\(\{r_t\}\)に分解する作業です。
処理は大きく内部ループと外部ループに分かれます。ループはそれぞれ\(n_i\)回と\(n_o\)回行います。内部ループでは\(T\)と\(S\)を計算し、外部ループでは残余を計算します。
図示すると以下のようになります。ステップは末尾のアルファベットを除けば、Cleveland, Cleveland, McRae and Terpenning (1990)の説明に対応しています。
周期部分列(cycle-subseries)は、\(y_t - \tau_t^{k + 1}\)の季節ごとにまとめた部分列です。季節の数\(n_p\)だけ部分列がとれます。今回のデータセットの場合、1月1日から開始の1週から53週までがひとつの季節になります。\(t=1, 54, 107, \cdots, 1326\)は、2001年,2002年,2003年,…,2026年のそれぞれ第20週を指す部分列になります。同様に\(t=2, 55, \cdots\),\(t=3, 56, \cdots\)といった部分列をつくれます。53周期ですから、53部分列がとれます。
周期部分列それぞれの前後に1期づつ拡張し、それぞれloess平滑化します。拡張された期の\(y_{(\cdot)}\)はNAとし、拡張されていない期のデータから\(\beta(\cdot)_0\)を推定します。拡張平滑化周期部分列も\(n_p\)あるので、全体となる拡張平滑化周期列\(\{c_t^k\}\)では\(2n_p\)拡張されることになります。
Step 2b, Step 3d, Step 6のloess平滑化のウェイトは記載されていませんが、それぞれ\(\{r_t\}\)から頑強性ウェイト列\(\{\sigma_t\}\)を、\(x_t\)から距離ウェイト\(w_s(x_t)\)を計算します。
Step 3a, 3b,
3cの中心化移動平均を3回かける部分では、拡張した系列を縮小しています。\(n_p\)期移動平均をかけると、前後にそれぞれ\((n_p-1)/2\)だけNAが入ることになります。よって、\(2(n_p-1)/2 + 2(n_p-1)/2 + 2(3-1)/2 =
2n_p\)縮小するので、\(l_t^{k+1}\)では元に長さに戻ります。
\(l_t^{k+1}\)は、周期列の中のローパス成分トレンド項になります。よって周期列からこれを除くと、真の季節変動になります。
終了時の\(\{\tau_t^{n_o}\}\)と\(\{s_t^{n_o}\}\)と\(\{r_t^{n_o}\}\)が求める系列です。
実践してみます。
s.year <- as.integer(gsub("^Y([0-9]+).*$", "\\1", rownames(df01)[1]))
s.week <- as.integer(gsub("^.*W", "", rownames(df01)[1]))
r_ts <- ts(df01$temp.avg, start = c(s.year, s.week), frequency = cycle_length)
r_stl <- stl(r_ts, s.window = "periodic")第1引数はtsオブジェクトが入るので、frequencyに53を入れてtsオブジェクトr_tsを作成し、指定しています。startは期の開始時点を指定します。
s.windowはStep 2bのLoess平滑化に用いる\(n_s\)を定める引数です。7以上の奇数が推奨されます。s.degreeはそのとき\(d\)に指定するdₛに該当します。"periodic"を指定すると、Loess平滑化ではなくて部分周期列ごとの平均値が入ります。
今回は指定していませんが、他にも引数はあります。innerで説明の\(n_i\)、outerで\(n_o\)を指定できます。robust = TRUEを指定すると、innerとouterのデフォルト値が変わります。s.jump,
t.jump,
l.jumpは、Loessを行う間隔を指定する引数で、処理の高速化ができます。Loessを飛ばす時点は、前後のLoess推定量から線形補間を行います。
応用では変更する必要がない引数もあります。l.windowはStep
3dのLoess平滑化に用いる\(n_l\)を指定する引数です。l.degreeはそのとき\(d\)に指定するdₗに該当します。t.windowはStep
6のLoess平滑化に用いる\(n_t\)を指定する引数です。t.degreeはそのとき\(d\)に指定するdₜに該当します。現論文のSummaryによると、\(n_l\)(l.window)は\(n_p\)以上の最小の奇数が、\(n_t\)(t.window)は\(1.5n_p/(1-1.5/n_s)\)以上の最小の奇数が推奨されており、デフォルトでは推奨値が設定されます。
結果オブジェクトのtime.seriesに、トレンド、季節変動、残余が入っています。他にもLoessのパラメーターなども入るので、必要に応じて確認しましょう。
Time Series:
Start = c(2001, 20)
End = c(2001, 25)
Frequency = 53
seasonal trend remainder
2001.358 3.003705 16.67056 1.2857339
2001.377 3.766479 16.67630 0.7429325
2001.396 4.285254 16.68204 1.0327022
2001.415 5.057290 16.68779 0.4834953
2001.434 5.536716 16.69353 -1.8159578
2001.453 7.024595 16.69927 -0.4952918[1] "time.series" "weights" "call" "win" "deg"
[6] "jump" "inner" "outer" 細かく引数を指定しなくても、だいたいは上手く行きます。ほぼデフォルトの上のSTLの推定結果をプロットします。
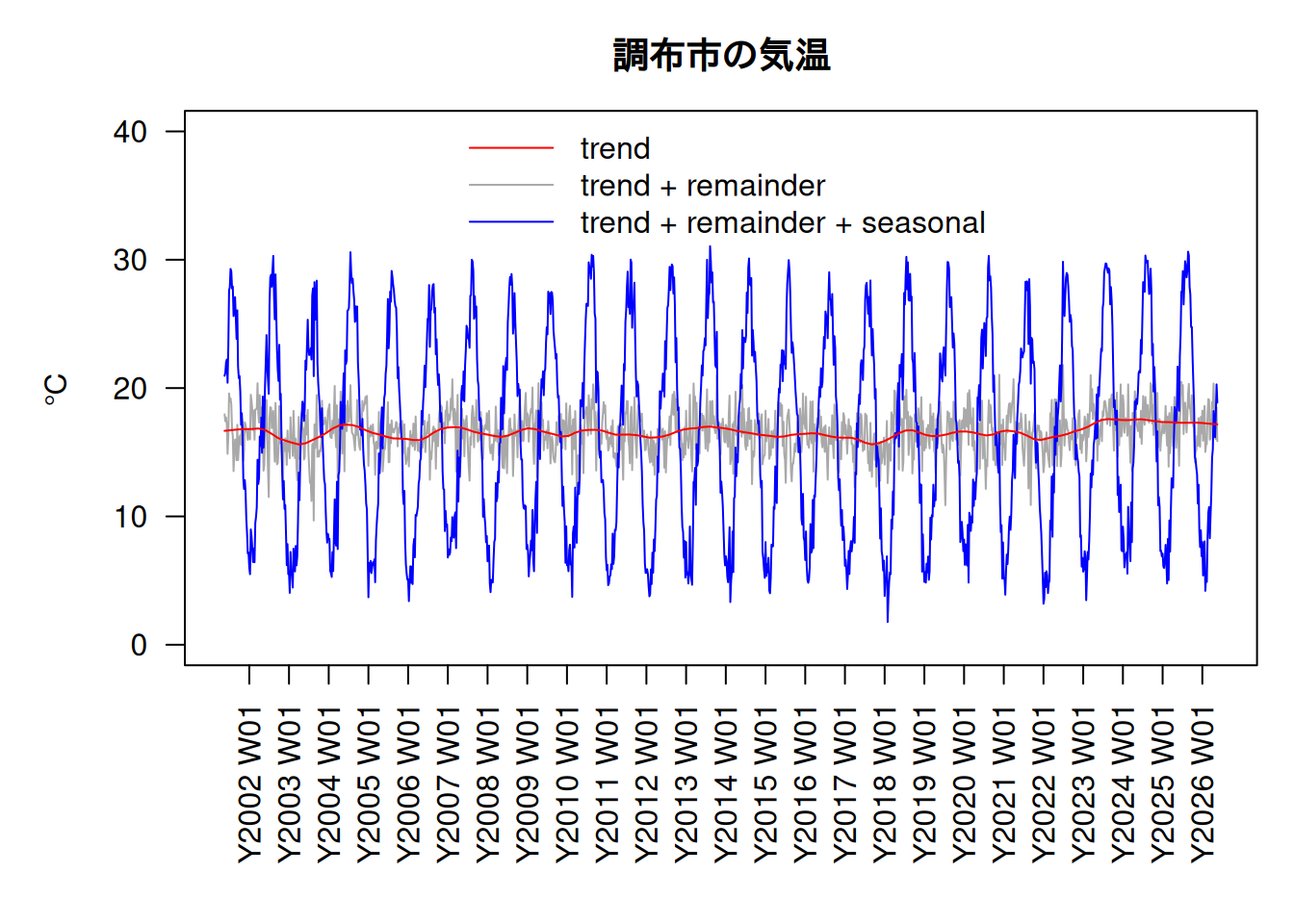
上手く分離できているようです。少なくとも残余に周期性やトレンドは見られません。
3.1 Seasonal-Diagnostic Plot
もう少し妥当性を細かく見たいときはSeasonal-Diagnostic Plotを表示しましょう。 これは、特定の周期部分列の季節変動値とそれに残余を加えた2つを、見やすいように特定の周期部分列の季節変動値の平均をそれぞれ引いてプロットした図です。
上の例そのままでは問題がなさすぎるので、s.window(\(n_s\))を13にしたものを描いてみます。
plot_sd <- function(r_stl, labels, season = 1, label.interval = 10){
s <- start(r_stl$time.series)
f <- frequency(r_stl$time.series)
with(r_stl, {
ptr <- seq(season, nrow(time.series), f)
t <- s[1] + (s[2] + ptr - 2) / f
time.series <- time.series[ptr, ]
c_s <- time.series[, "seasonal"] - mean(time.series[, "seasonal"])
c_r <- c_s + time.series[, "remainder"]
plot(c_r ~ t, axes = FALSE, xlab = "", ylab = "")
lines(t, c_s)
ptr2 <- seq(1, length(t), label.interval)
axis(1, lwd = 0, lwd.ticks = 1, at = t[ptr2], labels = floor(t[ptr2]))
axis(2, lwd = 0, lwd.ticks = 1, las = 1)
w <- par()$usr[2] - par()$usr[1]
h <- par()$usr[4] - par()$usr[3]
text(par()$usr[1] + w/20, par()$usr[3] + 19*h/20,
labels[(s[2] + season - 2) %% f + 1],
cex = 2, lwd = 2, adj = c(0, 1), col = "blue")
box()
})
}
plot_sds <- function(r_ts, s.window, labels = NULL, nr = 3, nc = 3){
r_stl <- stl(r_ts, s.window = s.window)
if(is.null(labels)) labels <- 1:frequency(r_ts)
par(mfrow = c(nr, nc), oma = c(1, 0, 3, 0.5), mar = c(3, 3, 0, 0))
for(i in as.integer(seq(1, frequency(r_stl$time.series), length.out = nr*nc))){
plot_sd(r_stl, labels, i)
}
if(is.numeric(s.window)) title(main = substitute(paste("Seasonal-Diagnostic Plot (", n[s]==a, ")"), list(a=r_stl$win["s"])), outer = TRUE)
else title(main = "Seasonal-Diagnostic Plot (periodic)", outer = TRUE)
}
plot_sds(r_ts, 13, sprintf("week: %d", 1:frequency(r_ts)))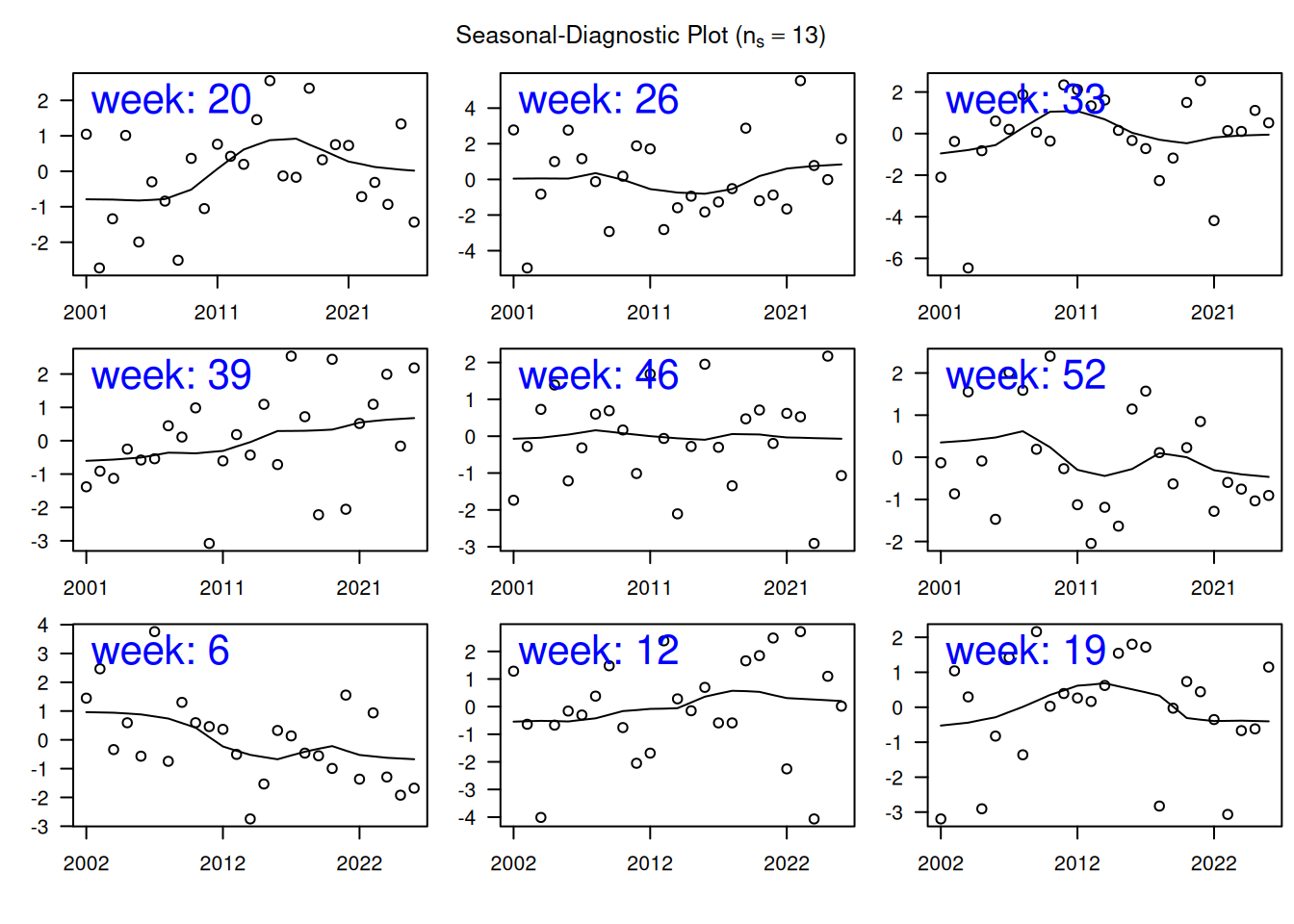
53週それぞれをプロットしても確認しきれないので、9週だけ表示しました。
スムーズではない部分周期列が多いですね。27や31にするとだいぶ一次方程式であらわせる変化に近づきます。