
内生性や不均一性の問題は生じないはずなのに,分布の裾野が厚くなって,ウェルチのt検定などで比較ができなかったり,最小二乗法やモーメント法やそれらのバリエーションになる推定方法で上手く推定できないときがあります.誤差項の分布がコーシー分布になっていて,中心極限定理が働いていないのかも知れません.
経験的にはそうは見かけないデータですが,何らかの都合で確率変数を確率変数で割った値を被説明変数にとると,原理的にコーシー分布を推定することになります.コーシー分布の導出を行い,その性質を確認した上で,コーシー分布でも上手く扱える統計手法の取り扱い方を抑えておきましょう.
1 コーシー分布の導出
正規分布に従う確率変数を,正規分布に従う確率変数で割ると,コーシー分布に従う確率変数になることが知られています.簡単のために,標準正規分布に従う確率変数の同時確率密度を考えましょう.
\[ u,v \sim \mathcal{N}(0, 1) \]
\[ f(u,v) = \frac{1}{\sqrt{2\pi}}e^{-\frac{u^2}{2}} \cdot \frac{1}{\sqrt{2\pi}}e^{-\frac{v^2}{2}} \]
変数変換をして基底を変えます.
\[ \begin{align*} x &= \frac{u}{v} \\ y &= v \end{align*} \]
ヤコビアンは
\[ \begin{vmatrix} \frac{\partial(u,v)}{\partial(x,y)} \end{vmatrix} = \begin{vmatrix} \frac{\partial u}{\partial x} & \frac{\partial u}{\partial y} \\ \frac{\partial v}{\partial x} & \frac{\partial v}{\partial y} \end{vmatrix} = \begin{vmatrix} y & x \\ 0 & 1 \end{vmatrix} = y \]
となります.
\(f(u,v)\)に\(u = xy, v = y\)を代入し,ヤコビアンを乗じたものが\(x\)と\(y\)の同時確率密度関数になります.
\[ \int_{-\infty}^\infty \frac{1}{2\pi}|y|e^{-\frac{1+x^2}{2}y^2}dy \]
\(y\)で積分をして\(x\)の確率密度関数を求めましょう.
\[ \begin{align*} &= \int_0^\infty \frac{1}{\pi}y e^{-\frac{1+x^2}{2}y^2} dy \end{align*} \]
\(w = (1 + x^2)y^2/2\)とし,変数変換をします.\(dy/dw = 1/(y(1+x^2))\)から,
\[ \begin{align*} &= \int_0^\infty \frac{1}{\pi}y e^{-w} \frac{1}{y(1+x^2)}dw \\ &= \frac{1}{\pi(1+x^2)} \int_0^\infty e^{-w} dw \end{align*} \]
ここで
\[ \Gamma(t) = \int_0^\infty e^{-s} s^{t-1} ds \]
に注意すると
\[ \begin{align*} = \frac{1}{\pi(1+x^2)} \end{align*} \]
と標準コーシー分布が導出できます.
2 コーシー分布の特性関数の展開
特性関数は確率密度関数をフーリエ変換したもので,あらゆる分布に存在し,また分布に応じて一意に定まるものです.その性質の確認のために,コーシー分布の特性関数を整理しておきましょう.
2.1 森・杉原『複素関数論』の補題7.3
確率分布を取り扱うときには便利そうな定理だったのですが,名前が無さそうなので教科書の説明を借りてきます.Jordanの不等式の説明は勝手に挟みました.
2.1.1 定理
\(f(x)\)は上半平面(\(0 \leq \mathrm{arg}\ z \leq \pi\))において\(|z| \rightarrow \infty\)のとき,一様に\(0\)に近づく正則関数1で,\(\Gamma_R\)は原点を中心とする半径\(R\)の上半平面にある半円周からなる積分路とする.このとき, \[ \lim_{R\rightarrow\infty}\int_{\Gamma_R} e^{ipz}f(z)dz = 0 \] が成り立つ.ただし,\(p>0\)とする.
2.1.2 Jordanの不等式
\[ 0 \leq x \leq \frac{\pi}{2} \]
において
\[ \frac{2x}{\pi} \leq \sin x \leq x \]
区間\([0, \pi/2]\)で,\(x - \sin x\)は非負の単調増加関数で,\(\sin x - 2x/\pi\)は\(x=\cos^{-1} 2/\pi\)を最大値,\(x=0,\pi/2\)で最小値\(0\)をとり,非負であるため.
2.1.3 証明
\[ I_R = \int_{\Gamma_R}e^{ipz}f(z)dz \]
とおく.\(\epsilon\)を任意の正数とするとき,\(R\)を十分大きくとれば,仮定から上半平面で\(R \leq |z|\)なるすべての\(z\)に対して\(|f(z)| < \epsilon\)とすることができる.このとき,
\[ |I_R| = \int_{\Gamma_R}|e^{ipz}||f(z)||dz| \]
であるが,\(z = Re^{i\theta}\)とおくと
\[ \begin{align*} |e^{ipz}| &= |\exp{(ipR\cos\theta - pR\sin\theta)}| \\ &= \exp{(-pR\sin\theta)} \\ |dz| &= |iRe^{i\theta}d\theta| = Rd\theta \end{align*} \]
となり,したがって
\[ \begin{align*} |I_R| &< \epsilon R \int_0^\pi \exp(-pR\sin\theta)d\theta \\ &= 2\epsilon R \int_0^{\pi/2} \exp(-pR\sin\theta)d\theta \end{align*} \]
が得られる.ここで,\(0\leq \theta \leq \pi/2\)において成り立ついわゆるJordanの不等式
\[ \frac{2}{\pi} \theta \leq \sin\theta \]
を使えば,
\[ \begin{align*} \int^{\pi/2}_0 \exp(-pR\sin\theta)d\theta &\leq \int^{\pi/2}_0 \exp(-2pR\theta/\pi)d\theta\\ &= -\frac{\pi}{2pR}\exp\bigg(-\frac{2pR}{\pi}\theta \bigg)\mid^{\pi/2}_0 \\ &= \frac{\pi}{2pR}(1 - e^{-pR}) \lt \frac{\pi}{2pR} \end{align*} \]
すなわち\(|I_R|\lt\pi\epsilon/p\)となり,したがって(7.13)が成り立つ.
2.2 コーシー分布の特性関数
コーシー分布の確率密度関数は,位置パラメーターを\(x_0\),尺度パラメータを\(\sigma\)とすると
\[ f(x) = \frac{\sigma}{\pi} \frac{1}{\sigma^2 + (x - x_0)^2} \]
となります.
特性関数は,
\[ \begin{align*} \varphi(t) &= E\big[ e^{itX} \big] \\ &= \int e^{itx}\frac{\sigma}{\pi} \frac{1}{\sigma^2 + (x - x_0)^2} \\ &= \frac{\sigma}{\pi} \int \frac{e^{itx}}{(x - x_0 + i\sigma)(x - x_0 - i\sigma)}dx \end{align*} \]
となります.ここで複素平面上の\(-R\)と\(R\)を両端にとる上半円\(C_R\)の線積分を考えると
\[ \begin{align*} \int_{C_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz \\ = \int^R_{-R} \frac{e^{itx}}{(x - x_0 + i\sigma)(x - x_0 - i\sigma)}dx \\ + \int_{\Gamma_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz \end{align*} \]
となります.\(\Gamma_R\)は複素平面上の弧を通る経路です.
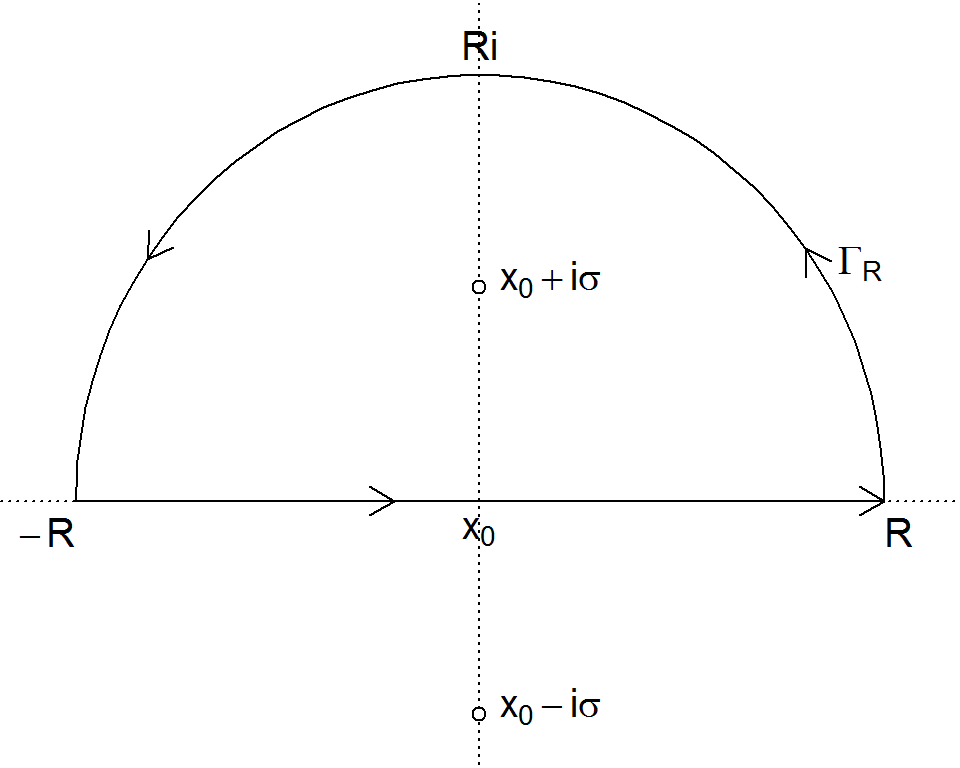
特異点は\(x_0 + i\sigma\)と\(x_0 - i\sigma\)になりますが,\(x_0-i\sigma\)は上半円\(C_R\)の内側に無いので,留数はよく知られた1位の極の計算技法により
\[ \begin{align*} \mathrm{Res}(i) &= \lim_{z \rightarrow x_0 + i\sigma} (z - x_0 - i\sigma) \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}\\ &= \frac{e^{it(x_0 + i\sigma)}}{2i\sigma} \end{align*} \]
となり,経路\(C_R\)の積分は,留数定理により
\[ \begin{align*} \int_{C_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz = 2 \pi i \frac{e^{it(x_0 + i\sigma)}}{2i\sigma} \end{align*} \]
となります.
一方,\(t>0\)のとき,
\[ \lim_{|z| \rightarrow \infty} (z - x_0 + i\sigma)(z - x_0 - i\sigma) = \infty \]
となるため,森・杉原『複素関数論』の補題7.3より
\[ \lim_{R\rightarrow\infty} \int_{\Gamma_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz = 0 \]
となります.
\[ \int^R_{-R} \frac{e^{itx}}{(x - x_0 + i\sigma)(x - x_0 - i\sigma)}dx \]
\[ = \int_{C_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz - \int_{\Gamma_R} \frac{e^{itz}}{(z - x_0 + i\sigma)(z - x_0 - i\sigma)}dz \]
であるため,コーシー分布の特性関数は
\[ \begin{align*} \varphi(t) &= \frac{\sigma}{\pi} \lim_{R\rightarrow\infty} \int^R_{-R} \frac{e^{itx}}{(x - x_0 + i\sigma)(x - x_0 - i\sigma)}dx\\ &= e^{i t x_0 - \sigma t} \end{align*} \]
と整理できます.\(t<0\)のときは,\(z=-k\)で変数変換を行なうと,\(\exp{(itz)} = \exp{(i(-t)(-z))} = \exp{(i(-t)k)}\)と補題7.3を使えるようにでき,1位の極が\(-x_0 + i\sigma\)になることに注意すると
\[ \begin{align*} \varphi(t) &= e^{i t x_0 - \sigma (-t)} \end{align*} \]
となることがわかります.\(0 \lt t\)と\(0 \gt t\)の場合をまとめると
\[ \begin{align*} \varphi(t) &= e^{i t x_0 - \sigma |t|} \end{align*} \]
と,よく知られた簡素な形式になります.
3 コーシー分布の性質
t検定や線形回帰が使えないことを確認しましょう.
3.1 期待値が定義されない
実際に期待値の計算をしてみると
\[ \begin{align*} E[x] &= \int^\infty_{-\infty} x \bigg[ \frac{1}{\pi} \frac{\sigma}{\sigma^2 + (x-x_0)^2} \bigg] dx \\ &=x_0 + \frac{\sigma}{\pi} \int^\infty_{-\infty} \frac{x - x_0}{\sigma^2 + (x-x_0)^2} dx \\ &=x_0 + \frac{\sigma}{\pi} \lim_{R_1,R_2\rightarrow\infty} \int^{R_2}_{-R_1} \frac{z}{1 + z^2} dz\qquad(z = \frac{x - x_0}{\sigma}) \\ &=x_0 + \frac{\sigma}{2\pi} \lim_{R_1,R_2\rightarrow\infty} \bigg[ \log(1 + z^2) \bigg]^{R_2}_{-R_1} \\ &=x_0 + \frac{\sigma}{2\pi} \lim_{R_1,R_2\rightarrow\infty} \log{\bigg(\frac{1 + R_2^2}{1 + R_1^2}\bigg)} \end{align*} \]
となるのですが,最後の行の右辺第2項に値が存在しません.
3.2 コーシー分布の再生性
検定や推定がしづらいのに,安定的なのがコーシー分布です.特性関数が同じならば,同じ分布になることから,再生性を確認しましょう.
3.2.1 線形結合はコーシー分布
2つの確率変数の線形結合の特性関数は,それぞれの特性関数を乗じたものとなります.
確率変数\(x,y\)の線形結合\(z = \alpha x + \beta y\ (\alpha,\beta \in \mathbb{R})\)の特性関数は
\[ \begin{align*} \varphi_{f+g}(t) &= \int_{-\infty}^\infty e^{izt} \int_{-\infty}^\infty f\bigg(\frac{z - \beta y}{\alpha}\bigg)g(y) dy dz\\ &= \int_{-\infty}^\infty g(y) \bigg( \int_{-\infty}^\infty e^{izt} f\bigg(\frac{z - \beta y}{\alpha}\bigg) dz \bigg) dy \\ &= \int_{-\infty}^\infty g(y) \bigg( \int_{-\infty}^\infty e^{i\frac{z - \beta y}{\alpha}\alpha t} e^{\beta y}{\alpha}t f\bigg(\frac{z - \beta y}{\alpha}\bigg) dz \bigg) dy \\ &= \int_{-\infty}^\infty e^{iy\beta t} g(y) \bigg( \int_{-\infty}^\infty e^{i\frac{z - \beta y}{\alpha}\alpha t} f\bigg(\frac{z - \beta y}{\alpha}\bigg) dz \bigg) dy \\ &= \int_{-\infty}^\infty e^{iy\beta t} g(y) dy \int_{-\infty}^\infty e^{iw \alpha t} f(w) dw \\ &= \varphi_f(\alpha t) \cdot \varphi_g(\beta t) \end{align*} \]
正規分布の特性関数には接近しません.
3.2.2 平均もコーシー分布
コーシー分布に従う2つの確率変数の平均はコーシー分布に従います.
\[ \begin{align*} \varphi_{f+g}(t) &= e^{i \frac{t}{2} x_{0f} - \sigma_f |\frac{t}{2}|}e^{i \frac{t}{2} x_{0g} - \sigma_g |\frac{t}{2}|} \\ &= e^{i t \frac{x_{0f} + x_{0g}}{2} - \frac{\sigma_f + \sigma_g}{2} |t|} \\ \end{align*} \]
i.i.d.であれば,元の分布に従い,パラメータは変化しません.サンプルサイズを大きくしていっても,その平均の推定量は改善されません.
4 コーシー分布とのつきあい方
原理的に中心極限定理に依存した分析手法が使えないコーシー分布ですが,実際にシミュレーションしてみると確かにt検定もOLSもうまく動きません.しかしランクを用いた分析手法を使うと,コーシー分布に従う確率変数でも上手く分析することができます.
4.1 二標本のランク検定
コーシー分布には期待値がないので,それに従うサンプルの平均や分散の差は上手く検定できませんが,2標本それぞれからの観測値\(X_1,X_2\)において\(P(X_1 \le X_2) + P(X_1=X_2)/2 = 0.5\)を帰無仮説とするランク検定は問題なく使えます.
ただし,伝統的に使われてきたマン=ホイットニーのU検定(ウィルコクソンの順位和検定)は比較するに二標本の分散やサンプルサイズが大きく異なると精度が落ちる事が知られており,現在では代わりにBrunner-Munzel検定を使うことが推奨されています.
対応しているパッケージは色々あるのですが,比較的最近開発されたbrunnermunzelパッケージは速度に優れ,精度も検証され改良されたので安心感があります.
library(brunnermunzel)
set.seed(20230303)
n <- 100
y1 <- rcauchy(n)
y2 <- rcauchy(n)
brunnermunzel.test(y1, y2)
Brunner-Munzel Test
data: y1 and y2
Brunner-Munzel Test Statistic = 1, df = 2e+02, p-value = 2e-01
95 percent confidence interval:
5e-01 6e-01
sample estimates:
P(X<Y)+.5*P(X=Y)
6e-01 4.2 ランク基準推定
Rfitパッケージで提供されている手法で,Kloke and McKean
(2012) "Rfit:
Rank-based Estimation for Linear Models," The R Journal,
Vol.4(2)にアルゴリズムの概要と利用方法の詳細が書いてあるので説明する必要はないのですが,ランク基準線形モデル推定はランク2を用いた線形回帰で,OLSでは一致推定量が得られない誤差項がコーシー分布である場合なども,頑強な結果を示してくれます.また,ノンパラ手法の紹介ページで存在を知ったのですが,カーネル回帰のように大きなサンプルサイズが必要になるわけではないです.
モデルと推定はそうややこしくなく,正規化したら以下の条件を満たすようにできるスコア関数\(\varphi\)を定義して,
\[ \int_0^1 \varphi(u)du = 0, \quad \int_0^1 \varphi(u)^2 du = 1 \]
誤差項からつくったランクを,\((0,1)\)の範囲に収まるようにサンプルサイズ\(n\)で割った値を,スコア関数に入れた値を,誤差項と乗じたものの総和を,最小化するように最適化アルゴリズムで推定します.
\[ \newcommand{\argmin}{\mathop{\rm arg~min}\limits} \begin{align*} u &= y-X\beta \\ \parallel u \parallel_\varphi &= \sum^n_{i=1} \varphi\bigg(\frac{\mathrm{Rank}(u_i)}{n + 1}\bigg)u_i \\ \hat{\beta}_\varphi &= \argmin_{\beta} \parallel u \parallel_\varphi \end{align*} \]
\(y\)は被説明変数のベクトル,\(X\)は説明変数の行列,\(\beta\)はその係数,\(u\)は残差のベクトルです.スコア関数は幾つかオプションがあり,標準では以下のWilcoxon Scoreが使われます.
\[ \varphi_{WS}(u) := \sqrt{12}(u-0.5) \]
ランク基準推定量は一致性と漸近正規性があって,
\[ \hat{\beta}_\varphi \overset{a}{\sim} \mathcal{N}(\beta, \gamma_\varphi (^t\!XX)^{-1}) \]
と書くことができ3,OLSと同様に検定が扱えるのが利点です.\(\gamma_\varphi\)はスケールパラメーターで,Koul et al. (1987)4で提案されている方法で推定します.
試しに誤差項がコーシー分布と正規分布に従う2つのサンプル生成して,ランク基準推定とOLSで推定量の比較をしてみましょう.
4.2.1 データセット
データ生成モデルは\(y = 1 + 2x - 3z + \epsilon\)で,\(\epsilon\)がコーシー分布もしくは正規分布に従うとします.
4.2.2 誤差項がコーシー分布に従うときの推定
誤差項がコーシー分布に従うときは,OLSの推定量はデータ生成プロセスとかけ離れた値になる一方,ランク基準推定はそこそこの精度で推定ができています.漸近的に正規分布に一致するのを活かしてt値が計算されていますね.
次のパッケージを付け加えます: 'Rfit'以下のオブジェクトは 'package:numDeriv' からマスクされています:
gradCall:
rfit.default(formula = y_c ~ x + z + g, data = df01)
Coefficients:
Estimate Std. Error t.value p.value
(Intercept) 1.093 0.380 2.88 5.0e-03 **
x 2.124 0.108 19.75 < 2e-16 ***
z -3.404 0.370 -9.20 2.2e-14 ***
g1 -0.378 0.548 -0.69 4.9e-01
g2 -0.146 0.546 -0.27 7.9e-01
---
Signif. codes: 0 '***' 1e-03 '**' 1e-02 '*' 5e-02 '.' 1e-01 ' ' 1
Multiple R-squared (Robust): 7e-01
Reduction in Dispersion Test: 55 p-value: 0
Call:
lm(formula = y_c ~ x + z + g, data = df01)
Residuals:
Min 1Q Median 3Q Max
-337.1 -0.3 2.3 9.1 34.9
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 4.96e-01 6.92e+00 0.07 0.94
x 2.44e+00 1.93e+00 1.26 0.21
z -6.78e+00 6.63e+00 -1.02 0.31
g1 -1.31e+01 9.82e+00 -1.34 0.19
g2 -1.94e+00 9.79e+00 -0.20 0.84
Residual standard error: 38 on 85 degrees of freedom
Multiple R-squared: 0.0491, Adjusted R-squared: 0.00433
F-statistic: 1.1 on 4 and 85 DF, p-value: 0.3644.2.3 誤差項が正規分布に従うときの推定
OLSもランク基準推定も大差のない結果となっています.
Call:
rfit.default(formula = y_n ~ x + z + g, data = df01)
Coefficients:
Estimate Std. Error t.value p.value
(Intercept) 1.11e+00 1.89e-01 5.88 7.7e-08 ***
x 2.05e+00 5.12e-02 40.00 < 2e-16 ***
z -3.03e+00 1.76e-01 -17.19 < 2e-16 ***
g1 -8.86e-02 2.61e-01 -0.34 0.74
g2 9.24e-02 2.60e-01 0.36 0.72
---
Signif. codes: 0 '***' 1e-03 '**' 1e-02 '*' 5e-02 '.' 1e-01 ' ' 1
Multiple R-squared (Robust): 9e-01
Reduction in Dispersion Test: 2e+02 p-value: 0
Call:
lm(formula = y_n ~ x + z + g, data = df01)
Residuals:
Min 1Q Median 3Q Max
-3.180 -0.706 0.099 0.663 1.756
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 9.76e-01 1.80e-01 5.42 5.4e-07 ***
x 2.01e+00 5.01e-02 40.15 < 2e-16 ***
z -3.05e+00 1.72e-01 -17.69 < 2e-16 ***
g1 -1.80e-02 2.55e-01 -0.07 0.94
g2 1.07e-01 2.54e-01 0.42 0.68
---
Signif. codes: 0 '***' 1e-03 '**' 1e-02 '*' 5e-02 '.' 1e-01 ' ' 1
Residual standard error: 1 on 85 degrees of freedom
Multiple R-squared: 0.957, Adjusted R-squared: 0.955
F-statistic: 468 on 4 and 85 DF, p-value: <2e-164.2.4 モデル選択
モデル選択はlmのanovと同様にできます.
Drop in Dispersion Test
F-Statistic p-value
0.30283 0.73952 4.2.5 分散分析
一元配置分散分析はoneway.rfitで,n元配置分散分析はraovでできます.
r_oneway_anova <- with(df01, oneway.rfit(y_c, g)) # 一元配置分散分析
summary(r_oneway_anova, method = "tukey") # 多重比較の補正をして結果表示
Multiple Comparisons
Method Used tukey
I J Estimate St Err Lower Bound CI Upper Bound CI
1 1 2 -1e+00 2 -5 2
2 1 0 4e-02 2 -4 4
3 2 0 -1e+00 2 -5 24.2.6 OLSとの使い分け
ランク基準推定は一致推定量ですが,有効推定量ではないです.また,OLSの場合は内生性や不均一分散やパネルデータを処理するためのパッケージが各種揃っていますが,ランク基準推定を用いる場合は自分でコーディングをしないといけない事が現状では多いです.原則としてはOLSを使う方がよいでしょう.
ある大きさより大の\(R\)で正則であればよいです.↩︎
Rの
rankで計算した値が使われています.↩︎リファレンスで参照されているテキストの他に,Hettmansperger, McKean and Sheather (1997) "Rank-Based Analyses of Linear Models" Handbook of Statistics, Vol.15, pp.145–173に説明があります.ただし,具体的な証明はHeiler and Willers (1988) “Asympotic normality of r-estimates in the linear model,” Statistics: A Journal of Theretical and Applied Statistics, Vol.19(2), pp.172–184などを読まないと確認できません.↩︎
Koul et al. (1987) "An Estimator of the Scale Parameter for the Rank Analysis of Linear Models under General Score Functions" Scandinavian Journal of Statistics, Vol.14(2), pp.131–141↩︎